 Summary: DNA from genetic cousins will be used to recreate the genomes of unknown ancestors who reside completely behind brick walls. While traditional research will often be able to provide a potential identity for the recreated genome, sometimes the individual will be known only by his or her DNA.
Summary: DNA from genetic cousins will be used to recreate the genomes of unknown ancestors who reside completely behind brick walls. While traditional research will often be able to provide a potential identity for the recreated genome, sometimes the individual will be known only by his or her DNA.
Into the Future!
Long-time readers of The Genetic Genealogist know that in addition to writing about the latest developments in genetic ancestry testing, I occasionally write about the future of genetic genealogy based on current trends and developments. This is something I’ve been doing since at least 2007, with posts like “The Future of Genetic Genealogy” and “A Single Colon Cancer Gene Traced to 1630 – The Future of Genetic Genealogy?”
In a recent post entitled “The Science Fiction Future of Genetic Genealogy,” I made some of my boldest predictions, including that – armed with massive databases – testing companies will be able recreate ancestors’ genomes (including the ancestors’ facial appearance, hair color, eye color, health, and traits, among other features), build family trees de novo, find both genetic & genealogical relatives, and map your DNA to specific ancestors, all with nothing more than a cheek swab.
Family History in 2050
Earlier this month, there was a post on the FamilySearch Blog entitled “Family History in 2050: DNA’s Impact.” Although the post has since been removed, it is available via the Internet Archive and Google cache. It is unfortunate that the post was removed, as it actually contained some interesting material and spurred some thoughtful commentary, both in the comments and at other blogs (see, e.g., “DNA’s Impact – A 2050 Look” – although I don’t agree with everything in Tanner’s post, it’s another important viewpoint).
In the FamilySearch post, which is lighthearted and jesting, the author jokes that by 2035 “only DNA evidence would be accepted for ancestral proof” because written records were “too unreliable, frequently falsified, and open to a wide variety of interpretations, making conclusions unscientific.”
Further, using massive databases including all types of DNA testing, there was an intentional switch in 2035 to using “four-symbol codes unique to each living person’s 16,384 ancestors stretching back 15 generations in time,” rather than a traditional pedigree. So everyone in the world family tree was identified by their DNA code rather than their name.
It was a fun post, and I recommend you read it (“Family History in 2050: DNA’s Impact“).
Using DNA on the Other Side of the Brick Wall
Although known ancestors are not likely to be identified by DNA codes, it is likely that some of our ancestors will be identified by their reconstructed genome instead of their name, simply because their name is unknown. In other words, although there are ancestors who reside on the other side of persistent brick walls, the DNA of many these ancestors is still walking the earth and found in the databases of testing companies.
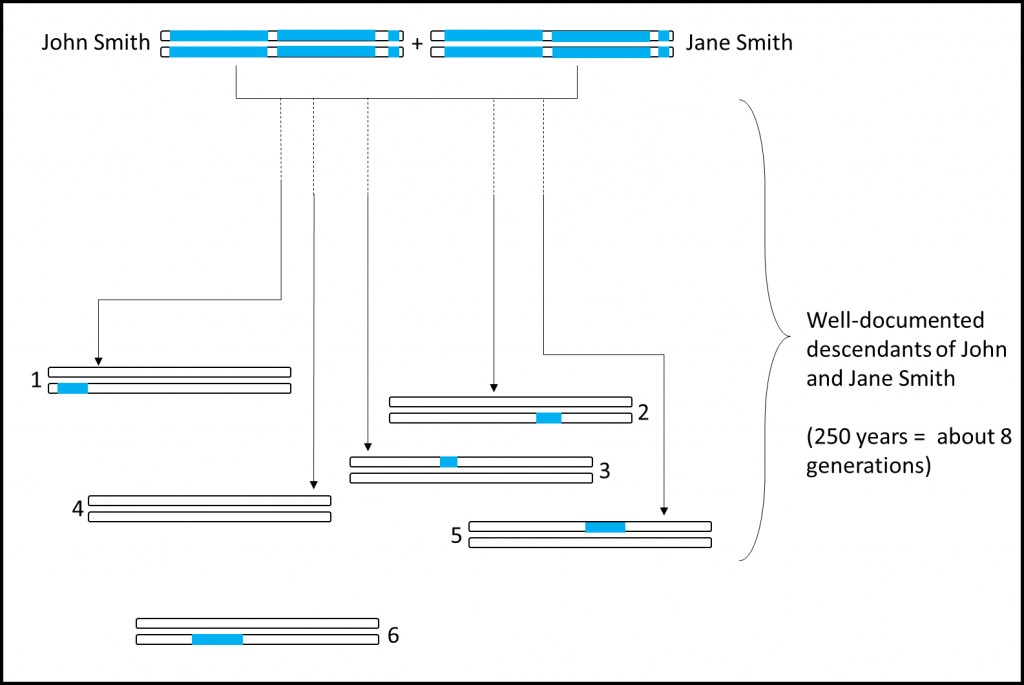
This DNA is already being used to recreate the genomes of known ancestors. AncestryDNA, for example, is reconstructing the genomes of our ancestors, including a couple living in the 1700s, as I wrote about a few months ago:
Next month at the American Society of Human Genetics 2013 meeting, researchers from AncestryDNA will present their work detailing the reconstruction of portions of the genomes of an 18th-century couple using detailed genealogical information and Identity-by-Descent (“IBD”) DNA segments from several hundred descendants of the couple in the AncestryDNA database. In other words, researchers identified several hundred descendants of a certain couple living in the 1700s and then used the DNA shared by those descendants to recreate as much of the couples’ genomes as possible. The abstract is entitled “Reconstruction of Ancestral Human Genomes from Genome-Wide DNA Matches,” and is freely available to the public. Unfortunately the abstract does not identify the 18th century couple in question.
Using DNA from descendants to recreate an ancestor’s genome would look something like this:
Now, imagine that the DNA is being used to recreate the genomes of unknown ancestors, which might work something like this:
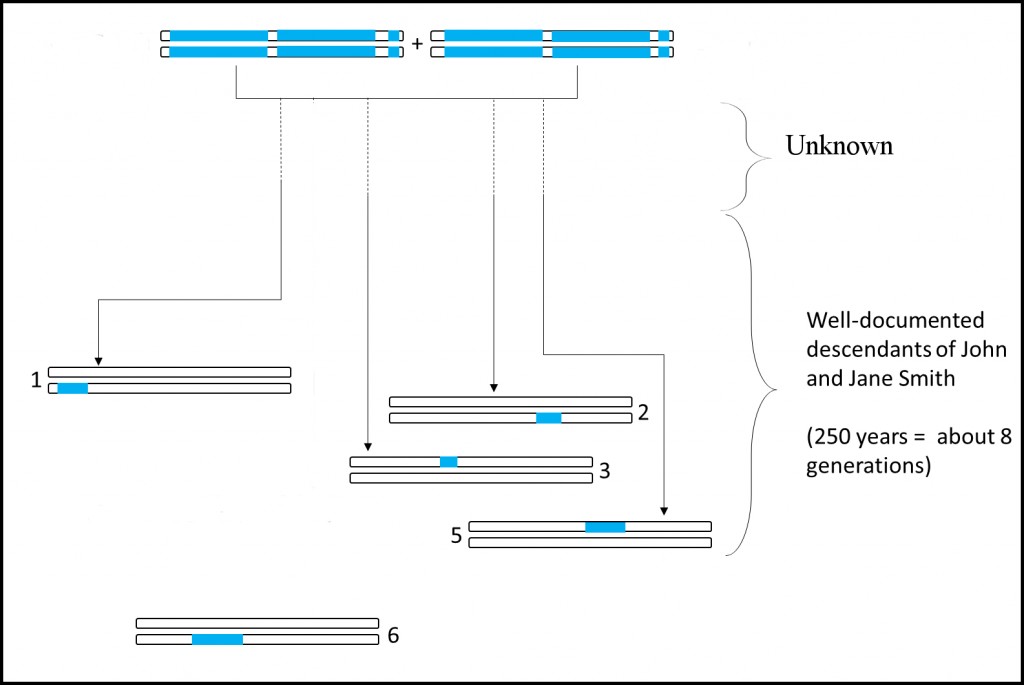
Note – should not say “Well-documented descendants of John and Jane Smith” – I’ll fix this.
You might ask how this can work without documented family trees. While it will certainly be more difficult, it is far from impossible.
An Example – Reconstructing an ‘Unknown’ Ancestor
Let’s assume that there is a large group of individuals who all trace their particular family tree to a small town in upstate New York in the early 1800’s. The lines all end there with no known shared ancestor, and there’s no traditional paper clues or shared surnames. However, all of these families are genetically related to one another, and based on their research they don’t share any other lines. If traditional research is exhausted, how can these relatives learn about their common ancestor?
DNA could potentially be used to recreate portions of the genome of the individual that they are all related to. This recreated genome will provide other information about the DNA-only ancestor, such as predicted eye color, hair color, medical conditions, and traits. It could also be used to find other relatives.
While I doubt the DNA-only ancestor will be given a set of four symbols, there will have to be some naming convention to give the individual an identity based on their reconstructed DNA. Perhaps NY-587, or AkronNY-1800s-1?
Now that there is a potential DNA-only ancestor identified, there may be clues that help identify the name of the ancestor, such as inherent phenotypic information (a medical problem, for example), or other relatives that now show as a match because of the recreated genome (a Johnson with a strong oral record for a family in the same town, for example). Seeing a scholarly article in a national genealogy journal with the title “Pinpointing the Likely Identity of a DNA-Reconstructed Ancestor in Akron, New York,” is not as far away as you might think.
DNA-Only Ancestors
While it will be ideal to identify the name and family of the DNA-only ancestor, for many of them it will be impossible, particularly for regions and times where records are too sparse for such identification (1700s & 1800s in Ireland, Native American ancestry, Poland pre-1800, the list goes on and on).
For each of these regions, there will be many different DNA-only ancestors. While we may not know their names, we can fill those gaps with any pieces of information we do have, or complement the DNA-only identification with historical events, the life of a common individual in that timeframe, etc.
For example:
- AkronNY-1800s-Male-1 – Likely lived in Akron, South County, New York between 1800 and 1820. Had at least 3 children, 2 sons and 1 daughter. Akron was first settled in 1797, so AkronNY-1800s-Male-1 was likely an early settler of the town, which prospered during its first two decades. Reconstructed genome #79543 is available at Reconstructed Ancestors <www.reconstructedancestors.com>. Earliest known descendants are:
- Grandchildren:
- Line #1 – Susannah (Unknown) Smith
- Line #2 – Rebekah (Unknown) Mullen
- Great-grandchild:
- Line #3 – Sarah (Unknown) Johnson
- Grandchildren:
Although this example focuses on someone who was suspected of existing in a particular time and place, it will also be possible to recreate the genomes of individuals who were previously completely unknown to history (i.e., for which there are absolutely no paper or oral records).
Although my family tree will not be made up entirely of DNA codes, it will eventually be populated with ancestors that I can only identify with their DNA.
Leave your thoughts below!
Great posting, Blaine! I can’t wait for all this to become reality. Don’t you want to reserve that domain, reconstructedancestors.com? If you don’t, I bet one of your readers will! 🙂
Thank you Bonnie! Same here, it’s going to be a lot of fun even watching this develop! I did reserve the domain ahead of time, only to prevent any nefarious uses. Thanks for reading!
I liked the ideas in “Family History in 2050: DNA’s Impact.” Genetic genealogy can reconstruct the genomes while documentologists debate and reconstruct the identities.
It was both fun and thought-provoking, and I was sad that it was removed. Luckily the content is still available a few places, and it’s triggered some good conversation. There’s no such thing as “removed” when you’re talking about the internet!
So with great interest I read this article, sent by a cousin into DNA work. I concentrate my time on inputting data, going thru records, books and from hundreds of cousins of all links, have been doing this about 35 years, just now passed the 500,000 name mark and thousands of pages, old letters, etc. to go thru and review. Have concentrated especially on ONE FAMILY, being the head of the National Family Organization, but now pretty defunct sine all I worked with before are deceased now. BUT of this family, extremely well documented, preserved, recorded over generations, proving back to the same immigrant of 1699 but now also records proving back to Butleigh, Somerset England 5 additional generations, with some siblings being mentioned as well. So of all this, the example mentioned of such a family tree, also I have some families of the immigrant mother’s brothers to date too, up to living persons today. So how can we use this to prove out your methods and to find if possible, a family tale of known, unproveable tales of historical interested persons claimed as ancestor?
Neither of those links now work. However, this one does: https://plus.google.com/+LineageKeeper/posts/iwanwj5e5mx