My great-grandmother belongs to Haplogroup H, and I always feel a little bad for her. Not that I have anything against Haplgroup H’ers, but they got the short end of the stick. You see, currently all mtDNA sequences are compared to the Revised Cambridge Reference Sequence (rCRS), an mtDNA sequenced derived in the early 1980’s and recently updated. Since the source of most of the mtDNA for that sequence belonged to Haplogroup H, people who belong to Haplogroup H often have no deviations at all and their sequencing results tend to be a little boring. Imagine if your mtDNA testing company sends your results and they say: “You belong to Haplogroup H, and your deviations from the rCRS are as follows: 0.†You see, a little dull.
Comparing everyone’s mtDNA to a randomly chosen sequence has always seemed so artificial to me. It was out of necessity of course, and maybe it will only be temporary. A recent paper in Nucleic Acids Research proposes that with the ready availability of many full-length mtDNA sequences, researchers can begin to compose a ‘consensus sequence.’ For the non-geneticists out there, a consensus sequence is sort of a master mtDNA sequence, the result of comparing many (or all) mtDNA sequences to create a single sequence that they can be used to describe them all.
The study used 827 recent high-quality full-length mtDNA sequences to create a consensus sequence and analyze the variability of human mtDNA. First and foremost, it is important that this is the very earliest stages of this type of study, and hopefully future research will use thousands of sequences from all over the globe (and from many different time frames using ancient mtDNA).
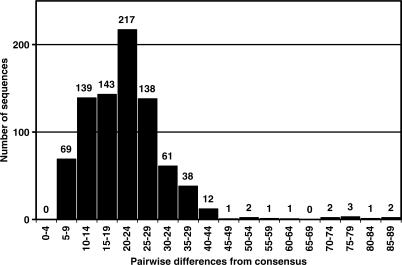
From the sequences studied, fully 84.1% of the mtDNA genome was invariant! Additionally, 43.8% of the variable sites were ‘personal mutations’, mutations found only in a single sequence. One of the most interesting pieces of information was that the sequences differed from the consensus by 21.6 nucleotides. Thus (if this number holds true with further research), if you were to randomly pick a person off the street, your mtDNA sequence will only differ, on average, by 21 or 22 nucleotides. The full range, however, was from 5 to 89 nucleotides, a pretty big range:
Another great piece of information was the variance between the rCRS and the human consensus generated by the study – 73, 263, 325+C, 750, 1438, 2706, 4769, 7028, 8860, 11719, 14766, and 15326. Interestingly, “[t]his list exactly parallels the changes necessary to go from the rCRS (Haplogroup H2a) through each of the intermediate haplogroups, to macrohaplogroup R.â€
I enjoyed that article, too, but I’m a bit skeptical that the “consensus sequence” will replace the CRS. There’s just too much literature that has reported differences from the CRS. I use the analogy of zero degrees longitude — that is a completely arbitrary starting point, but everything can be described in relation to it.
If we did use the consensus sequence as a starting point, then two people chosen at random would differ FROM EACH OTHER at an average of 2 x 21.6 nucleotides, or about 43.
The number of “private” mutations is encouraging for genetic genealogists hoping to narrow down their pool of matches to the closest relatives.
One small typo — the rCRS differs from the consensus at 315+C (315.1C as genealogy companies report it), not 325+C.
Ann – thanks for stopping by and leaving a comment. You make a great point about all the previous literature using the CRS – as I recall, even the scientists who released the rCRS adopted some unusual fixes so they wouldn’t upset all the literature that cited the CRS. And thank you for the typo fix!