The Shared cM Project is a collaborative research project that uses data from 100s of genealogists to generate shared DNA ranges and averages for nearly 50 different genealogical relationships. The most recent version of the Shared cM Project, Version 4.0, was released on March 27, 2020 (I had so much free time in the early days of the pandemic!). See “Version 4.0! March 2020 Update to the Shared cM Project!” Keep those submissions coming, I’m hoping to do an update in 2023!
Always Improving!
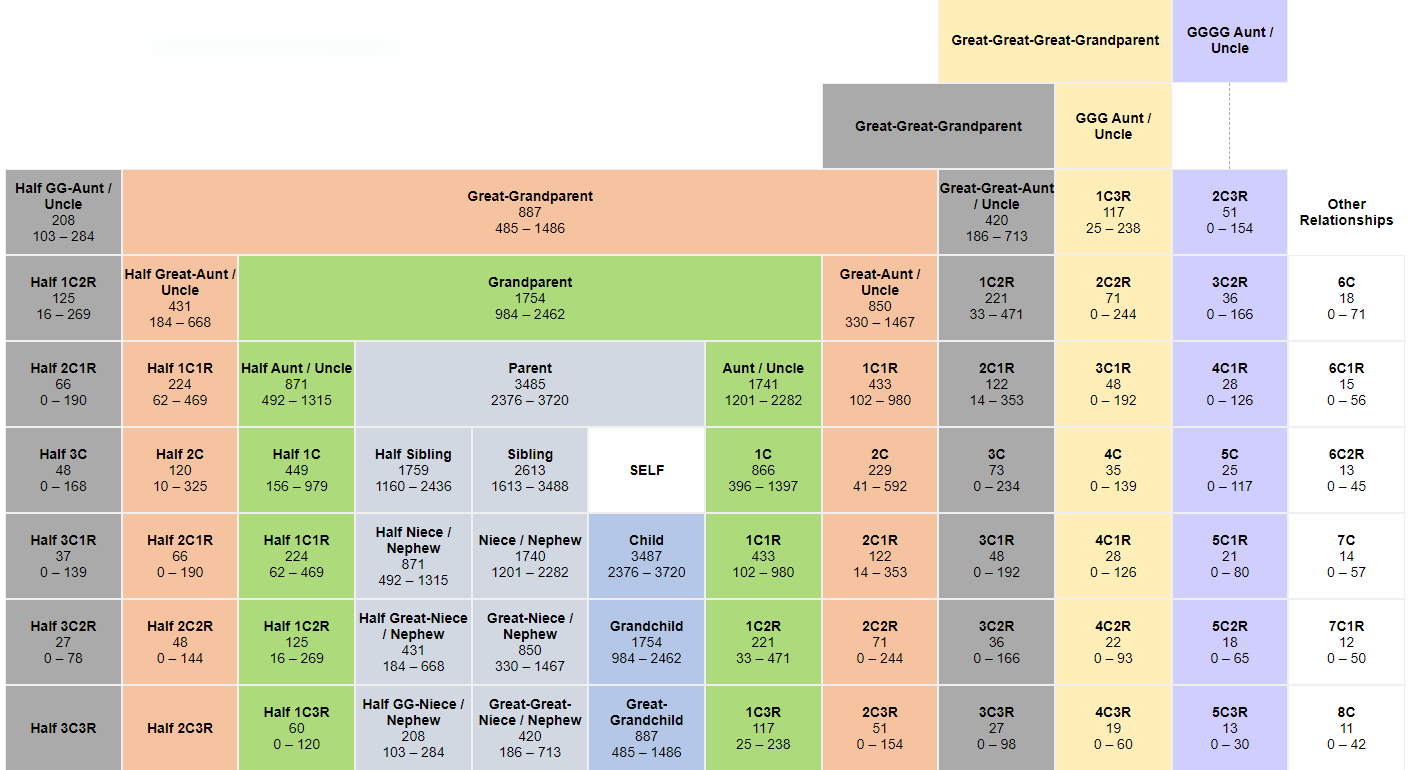
One of the enhancements to the Shared cM Project that has been on our minds since the creation of the project is the use of siblings and/or same-generation cousins to narrow down the list of possible relationships to a DNA match.
For example, my sister and are full siblings, and thus by definition we have the same genealogical relationship to all of our genealogical cousins. Sometimes this can be a challenging concept! This graphic shows how my sister (Sibling #1) and I (Sibling #2) have exactly the same genealogical relationship to this third cousin (3C):
![]()
Thus, in terms of genealogical relationships, my sister and I are effectively the same person. The same is true for me and my brother, and so on. We have exactly the same Genealogical Family Tree (see “Q&A: Everyone Has Two Family Trees – A Genealogical Tree and a Genetic Tree,” a blog post from nearly 13 years ago!).
However, my sister and I are NOT the same person when it comes to genetic relationships (unless we are identical twins of course!). We have different Genetic Family Trees. We can and often do share varying amounts of DNA with genetic cousins.
And we can leverage these varying amounts to gain insights into our genetic relationships!
The Shared cM Tool at DNA Painter
DNA Painter, the essential website created by the incredible Jonny Perl, hosts a FREE interactive version of the Shared cM Project at The Shared cM Project 4.0 tool v4. The tool allows you to enter a shared cM amount from a DNA match and visualize possible relationships. In the following example, I share 95 cM with Susan Smith:

I can go to the Shared cM Project tool at DNA Painter and enter in 95 cM to determine the possible genealogical relationships that a DNA match sharing 95 cM fits into:
Once we enter “95” into the input box, the Shared cM Project visualization changes from this:
To this, where only certain relationships are possible/likely given sharing of 95 cM:

However, this visualization only shows the possible genealogical relationships based on MY genetic relationship with Susan Smith. What if I could further narrow this down to include the possible genealogical relationships based on my SIBLING’S genetic relationship with Susan Smith?
Now I can! And you can too!
Jonny has graciously created a FREE modified version of the Shared cM Project tool that allows us to enter in two shared DNA amounts to identify the relationships for which BOTH entered amounts are possible/likely! This new tool is hosted at “The Shared cM Project 4.0 tool v4 with option to add a second amount.” And once again, it is completely FREE! I cannot begin to thank Jonny enough for all of his work, nor can I contain my amazement at his coding skills!! Thank you Jonny!
There are few requirements for this tool:
- A tested sibling or cousin (which tested cousins can be used for this tool is discussed below);
- Some access to those results (and there are many variations of access, including sharing DNA results as well as good old fashioned over-the-phone collaboration!);
- A DNA match to at least one of the tested siblings or cousins; and
- A difference in shared DNA amounts with that DNA match.
Requirement #4 is key! Although technically you can enter the same amount in both boxes, this doesn’t really help eliminate any relationships. And elimination is really the major goal here; by entering a second shared DNA amount, we hope to eliminate some of the possible relationships.
Generally, the greater the difference between the two siblings or cousins, the more valuable the tool will be.
Back to Our Example
We saw above that I share 95 cM with Susan Smith. Let’s examine my sister’s sharing with Susan Smith:

She shares NO DNA with Susan Smith! That will likely eliminate some possible relationships, so let’s take a look. We will enter 95 and 0 as entries into the interactive tool:
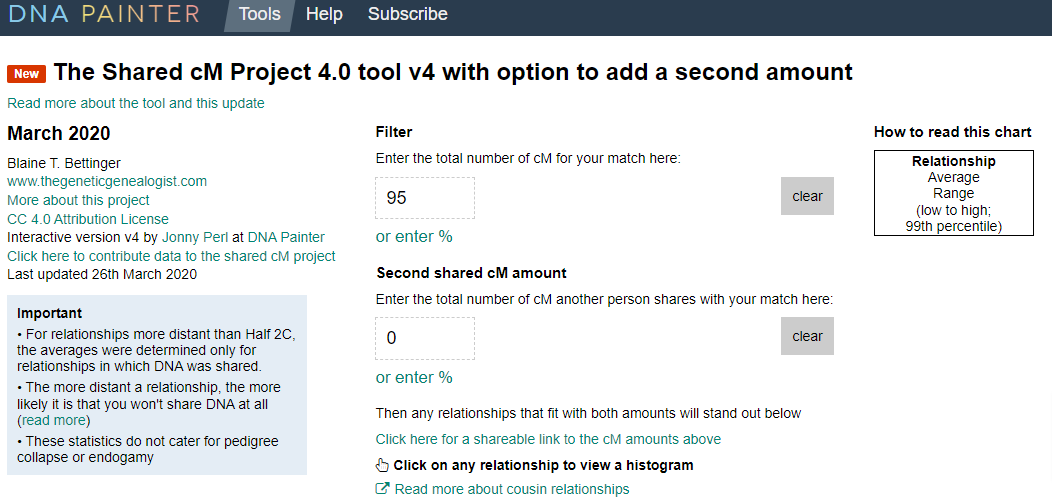
That results in a narrow band of possible/likely relationships:
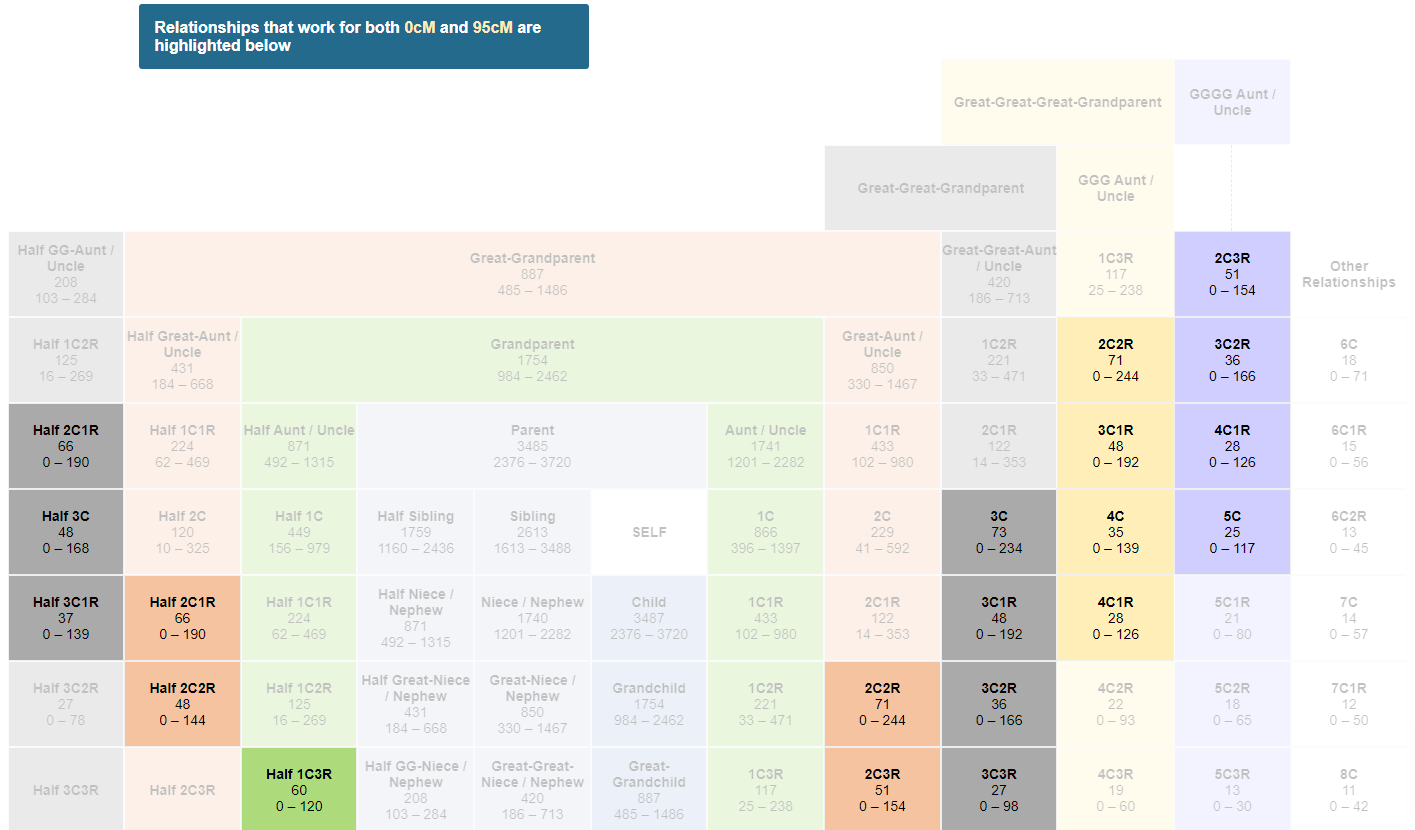
When comparing the visualization above for just 95 cM to this visualization for 95 cM and 0 cM, there is a really nice difference:

We eliminated 12 possible relationships!!
And as with the original version of the tool, don’t forget to click on the relationships to view the histograms, which are amazingly labeled with BOTH shared DNA amounts. Now this doesn’t always work when one result is 0 cM, so for the sake of showing you an example I’ve entered in 95 cM and 25 cM:

Note that the “The percentages below the graph give the proportion of cases above and below” the amount entered in the FIRST box. So you can always switch back and forth to see the two different percentages.
Also, neither the 95 cM nor 0 cM in this particular example are affected by the TIMBER algorithm at AncestryDNA (TIMBER only affects results of 90 cM or less), so I didn’t have to worry about that. If you have a shared amount of less than 90 cM and above 0 cM at AncestryDNA, you might consider using the pre-TIMBER amount especially if it provides a larger variation. But you can play around with this a little bit to experiment and find an approach you conclude is scientifically rigorous.
And there’s no reason this tool won’t work for cross-company comparisons! While there are variations in matching algorithms from company to company, and thus variations in shared amounts, this just isn’t going to have a huge impact on this tool. Remember that EVERY relationship prediction tool can only provide clues about possible/likely relationships! There is no tool in existence that can identify an exact genealogical relationship using ANY shared DNA amount, even parent/child (since there are other explanations for parent/child sharing that must be eliminated such as bone marrow donor, identical twin, and so on).
Although this automated implementation is new, genealogists have been using this methodology since the Shared cM Project was launched in 2015. It was always just a very manual process, and hopefully this new interactive tool will be beneficial to many people!
Who Can I Use With This Tool?
There are actually many relationships other than sibling that can be utilized. For example, the tool can work with cousins in the same generation as long as there is no additional relationship between yourself and the DNA match, or the cousin and the DNA match.
In the example illustrated by this graphic, Cousin #1 and Cousin #2 are both third cousins with 3C, and thus both their shared DNA amounts are relevant to that relationship in the same way, provided that neither Cousin #1 nor Cousin #2 has a second genealogical relationship to 3C via their unshared grandparents:
![]()
So the hypothesis would be that if Cousin #1 shares 74 cM with 3C and Cousin #2 shares 20 cM with 3C, all of that shared DNA comes from the same shared ancestral line and thus both amounts can be used to examine the relationship to 3C.
However, since some or all shared DNA can be lost in a subsequent generation, it is risky to use this tool for a relationship where the two individuals are not in the same generation. This includes relationships such as aunt/nephew, you and a 1C1R, you and a great-uncle, and so on.
However, the tool could work very well for the following relationships (NOT an exhaustive list, so be creative!):
- Full siblings – by definition, full siblings have the SAME genealogical relationship to all matches;
- Half siblings – can use this tool for relationships via the shared parent, provided there are no relationships via the non-shared parent;
- First cousins – can use this tool for relationships via the shared ancestor, provided there are no other genealogical relationships;
- Second cousins – can use this tool for relationships via the shared ancestor, provided there are no other genealogical relationships;
- And so on…
Of course the caveat is that we don’t always know when there are other genealogical relationships, so caution is ALWAYS needed and warranted. Confirmation bias is the greatest enemy of any genealogist!
What if I have Multiple Siblings/Cousins?
You might be asking, “Why can’t I enter values for three siblings?” The quick answer is because you don’t really need to!
It’s an easy decision if you only have a set of two siblings, or maybe yourself and a first cousin; you just enter the two results into the new user interface and utilize the output.
But what if you have three siblings? Or yourself and four 1C siblings?
You can utilize this new tool by selecting the best two shared DNA results. In general, use the two shared DNA results that are the MOST DIFFERENT! In other words, use the greatest possible range of shared DNA.
For example, returning to our Susan Smith example, my brother has also tested and shares 68 cM with Susan:
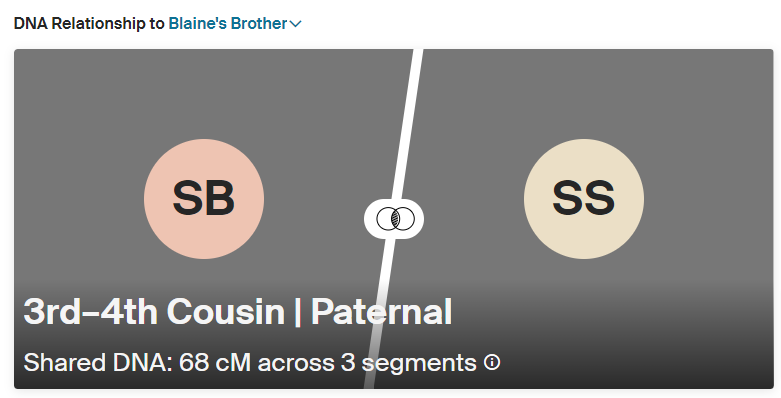
However, the difference between 95 cM (my shared amount with Susan) and 68 cM (my brother’s shared amount with Susan) is much less than the difference between 95 cM and 0 cM (my sister’s shared amount with Susan). Thus, out of these three results (95 cM, 68 cM, and 0 cM), I would use 95 and 0. I could also try 95 and 68, or 68 and 0, but I’m likely to get the best result using 95 and 0 cM.
Mom and Her Four Siblings
In another example, my mother and four of her siblings have tested, so I can mine their results to identify ranges. The siblings share the following amounts of DNA with a match:
- 133
- 112
- 111
- 103
- 99
So I would use 133 and 99, although this only eliminates a couple of relationships. In the following example, the siblings share these amounts of DNA with a second match:
- 101
- 54
- 54
- 37
- 31
So I would use 101 and 31, which does eliminate a couple of relationships.
In conclusion, I hope you find this enhancement of the Shared cM Project tool a valuable development! Check it out at “The Shared cM Project 4.0 tool v4 with option to add a second amount.” I thank Jonny for his amazing work, and I look forward to hearing how all of you use this tool!
Does this article give me hope in helping a friend identifying which one of two brothers is actually her birth father? The third brother died and his son is a fifth cousin, and one of the two left was really friendly and welcoming her to their family when he thought the deceased brother was her father. When the results of the deceased brother’s child’s DNA came in as a first cousin, neither of the two brothers will do DNA. The friendly one is married and has two grown children but his children will not do DNA. The other one is single but will not communicate with my friend. Will this new article help in this situation? Previously, on DNAPainter, all three brothers have the same percentage likelihood of being her birth father. Thanks.
I’m trying to do what you’re asking about. I’m looking to identify my paternal grandfather’s father. Because of surname changes in the family and Big-y testing, I know it’s most likely 1 of 4 brothers. As you point out the challenge is getting people to test. Also, one of mine doesn’t appear to have descendants.
Also, there could always be an unknown relative(s) out there.
Good luck.
I can only reproduce your example with shared DNA of 95cM and 0cM, by entering 0cM in the first (top) box and 95cM in the second (bottom) box.
When doing it the way you outline, it is not picking up that there is an amount (0cM) in the second box, and doesn’t show the desired result.
This looks VERY exciting!
I am a “visual learner”. I wonder if you’d consider producing a YouTube (or similar) video.
Thanks!
This is great! I’ve been doing this on paper for a long time. Now I don’t have to anymore! I would print out a relationship chart for the lowest match and the highest match of me and my siblings to a person, and compare them, X’ing out the relationships that didn’t appear on both printouts. Is the reason zero doesn’t work is because of dividing by zero? Would it help to use 1 instead of 0?
Private Question.
As I compare parent DNA with child DNA I notice that some portions of DNA appear to be sticky, ie it gets passed from a parent to a child entire.
I also notice that some DNA matches, which due to shared match data, must be distant cousins, can also have a portion of DNA that appears to be sticky.
Has any research been done into this?
Can you please explain why there is a range given for parents? Each parent should provide exactly half of each offspring’s autosomal genome. Is the range due to the sex chromosomes or measurement error? Thanks!
Differences in company analysis/reporting
Any chance of adding the option of offering other relationships for the second test? My aunt is the only other test I have in my family and we’re trying to resolve a brick wall at my 2xggf so our DNA matches
…often only share a small amount of DNA with us with a high degree of variability. Adding a second test seems like it would be a useful way to pinpoint what relationship we have with a DNA match.
Thanks.
I thought this would be fun to test with my sister and I. It seems to work pretty well with our first cousin, Great-Uncle, 1C1R and 2C. However, it really struggled with the comparison to my nephew who is my sister’s child. It said the only option to match both me at 1912 cM and my sister at 3468 cM was as a sibling. Obviously, that isn’t the answer. So if one of the two relationship is really close then extra caution is required.
Yes, if the siblings don’t have the same relationship to the person (meaning the person is a descendant of one of the siblings), the tool won’t work properly.
An enhancement suggestion : Why not combine this feature (“The Shared cM Project 4.0 tool v4 with option to add a second amount.” ) with that from Jonny’s “Beta version with updated probabilities”? This would combine the candidate relationships along with their estimated probability of occurrence to produce an overall probability of occurrence for each relationship. A H2C relationship has a 48% chance of occurring from the 95 Cm case, but only a 1% chance from the 0 Cm case or a .48x.01 = .0048 overall probability. A 3C relationship has a 29% chance of occurring from the 95 Cm case, but a 10% chance from the 0 Cm case or a .29x.10 = .029 overall probability. So, the 3C is more likely than a H2C in this example (.029/.0048 or 6 times more likely).
While the 95 Cm case would have us leaning towards the H2C as the most likely relationship, factoring in a second person suggests a different leading candidate relationship. This approach would actually benefit from having more than two within the same generation. Take an extreme example; suppose I had 1 sibling at 95 Cm but 3 others at 0 Cm. This would enable us to rule out even more of the candidate cases as likely not possible.
This suggestion would actually be the beginning of a WATO tool rev. 2. I am the DNA kit administrator for several relatives. I’d like to combine the WATO results for each relative into an “overall” WATO which would yield improved probabilities for the various hypotheses. And in my case, several of the relatives are not the same generation which would make the interface quite challenging.
Thanks!!
This is brilliant. Would this work where you have two mystery matches that you know are siblings, but do not know how they relate to you (a sort of mini-WATO).