Have you experienced this? You’ve identified a very clear cluster that includes numerous DNA matches that all descend from a single family, but you have no idea how this family links into your family tree. Try as you might, and despite building numerous trees, you can’t seem to figure out how these DNA matches and this single ancestral family link into your family tree. If this sounds familiar, you have an Unlinked Family Cluster!
Defining “Unlinked Family Cluster”
An Unlinked Family Cluster is a very specific phenomenon in genetic genealogy, one that is becoming increasingly common. We see more and more of these clusters for various reasons; the matching databases get larger and larger meaning that these clusters get larger and easier to identify. Additionally, the more we work with our closest DNA matches, the more we have very promising “left behind” matches that don’t fit into our known ancestry. Often, these “left behind” matches form a shared match cluster or a triangulated cluster around a specific family. This is an Unlinked Family Cluster.
This is how I define an Unlinked Family Cluster:
- Forms a cluster – The cluster may be formed by shared matching (without segment data), triangulation (with segment data), or a combination of the two.
- Not recent ancestry – The cluster does not represent recent ancestry (no parents, grandparents, great-grandparents).
- No close matches – Related to the previous point, the matches in the cluster are more distant matches usually in the range of about 20-50 cM. Although a very small number of matches in the cluster can be higher or lower, if there were many closer matches then placement of the cluster in the family tree should be solvable. Similarly, if the cluster is made up of more distant matches (less than 20 cM), it may be more likely to be a pile-up region rather than recent common ancestry.
- Large number of matches – The cluster includes a large number of matches, typically in the range of 25 or more DNA matches, sometimes 50 or more. While a cluster may have a smaller number of people, it may be difficult to reliably determine that a hypothesized common ancestor/couple of the cluster is actually the common ancestor/couple responsible for the cluster. Further, DNA matches from as many lines of descent from the identified common ancestor/couple (preferably through multiple different children) is preferred to lend further support to the identification. Many Unlinked Family Clusters have members from more than one testing company, but this isn’t a requirement.
- Same ancestral family – The members of the cluster have trees (that they built or that you built!) that include the same ancestral ancestor/couple. While it’s rare that all members of the cluster can track their ancestry back to the identified common ancestor/couple, usually most members of the cluster can do so.
- Not in your tree – The identified common ancestor/couple is not found in your known family tree. If they were, this would be a Linked Family Cluster!
I want to emphasize that an Unlinked Family Cluster can be formed by either shared matching, triangulation, or a combination of the two. Also, it is important to note that none of these methods of forming a cluster are better than another. Especially considering the size of these clusters, a shared match cluster is just as valid as a triangulation cluster, and vice versa. Both methods can help you identify members of the cluster, and then the genealogy steps in to solve the rest of the mystery!
My Example – The Unlinked Zufelt Cluster
I ran into my first Unlinked Family Cluster maybe 5-6 years ago while working through my mother’s DNA test results at AncestryDNA. I was working my way down her list of matches, assigning them to maternal and paternal (in the “old days” before AncestryDNA automated this process!) when I ran into a match not too far down her match list. “Iva Smith” (a pseudonym) shared 48 cM with my mother. Of course, when I first worked with the match, there was not “Paternal Side” (i.e., Parent 2) label, nor my notes!

I examined the match, first looking at the match’s tree and then at shared matching. The tree wasn’t very informative, except that Iva had ancestry from Upstate New York and Canada (as does my mother on her paternal side). None of the people/surnames in Iva’s tree matched mine, or even looked familiar.
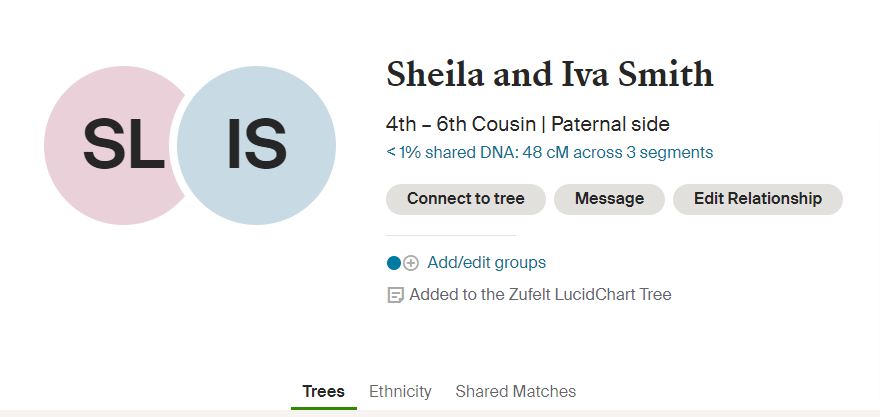
Interestingly, TIMBER had reduced this match from 72 cM to the reported 48 cM:

When I looked at shared matching, I saw a number of matches in the list, all sharing less than this 48 cM. While there were also some close family members, none of them were helpful in assigning a line (these close matches were either my mother’s siblings, descendants of my mother’s siblings, or my mother’s descendants, so completely unhelpful).
As I started to open the trees of these shared matches, and as I built out trees of these shared matches, I began to notice a pattern develop: the Zufelt surname (and variations thereof) appearing in every one of these trees. Over and over again, I would explore a shared match and would review their tree (although usually I would be building their tree!) and run into the Zufelt surname.
Not only would I run into the Zufelt surname, but it was the same Zufelt family over and over again. Each match (if a tree could be built!) could be traced back to Adam and Neeltje (Freer) Zufelt of Upstate New York. As the cluster grew with more tree building and an occasional new shared match showing up as more people tested, I could track these matches through three different children of Adam and Neeltje (Anthony, Elizabeth, and Henrich). I also found some matches through two of Adam’s brothers (Johann and Jacob).
Currently there are more than 50 matches in this cluster, all or most appearing as shared matches to each other, and all being descendants of this same Zufelt family. Of course, there are several matches in the cluster that cannot be tied into the family, usually do to MPEs (misattributed parentage events), tree errors, and so on.
Armed with the Zufelt surname, I also found matches at Family Tree DNA and MyHeritage that tied into this family.
The breakdown of matching (pre-TIMBER for AncestryDNA matches) is as follows:
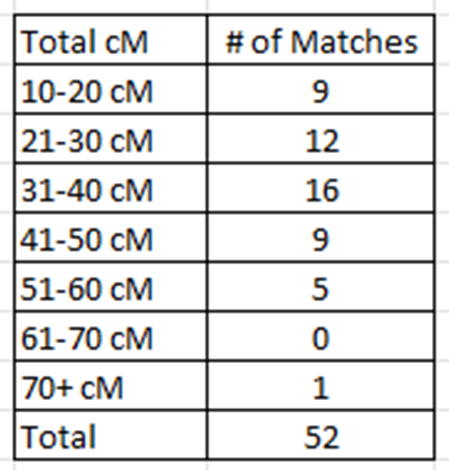
Despite the one very close match (Iva Smith at 72 cM), I was still unable to tie this Zufelt family into my family tree.
To help me keep track of the matches and the cluster, I created a descendancy chart in LucidChart that had each of the matches (including their username, the testing company, and the shared cM total) and their lineage back to the Zufelt couple. Below is a screenshot of the LucidChart for the Zufelt cluster. Please note that this is intentionally blurred to avoid identification of the matches.
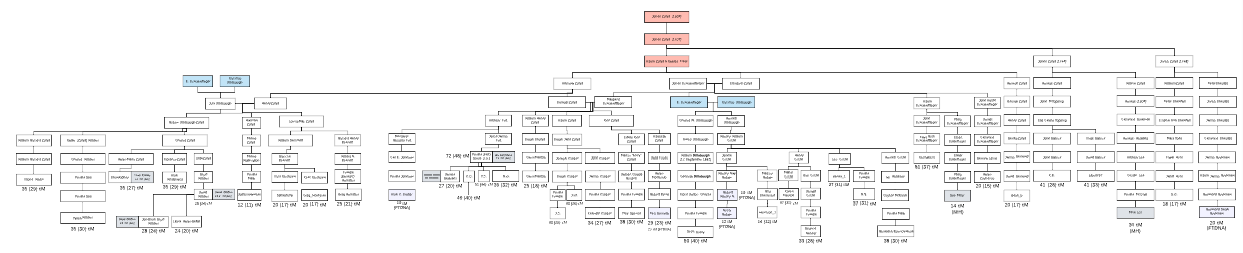
Unfortunately, despite all these matches, I could not place the Zufelt family anywhere within my family tree. Since these are my mother’s matches, I knew this family was on my maternal side. I could further narrow down the connection to my mother’s father’s family given both the location of this family (i.e., Upstate NY) and the fact that my mother’s mother came from Honduras and all of those matches are endogamous (and none of the Zufelt descendants shared this ancestry).
Although not particularly helpful to this particular shared match-based cluster analysis, I also had segment data for the cluster from matches at MyHeritage and Family Tree DNA:
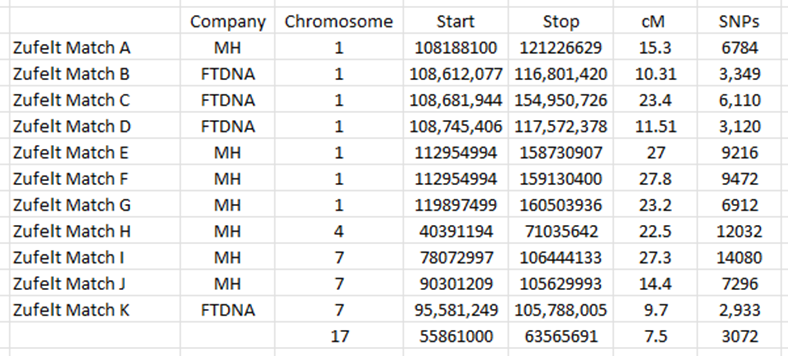
Remember that these are my mother’s matches and thus my mother’s segment data.
I didn’t match any of the Zufelts on chromosome 1. Indeed, when I look at this region of chromosome 1 on my Visual Phasing chromosome map (which shows me which grandparent I inherited my DNA from at any given chromosome location), I can see that I inherited DNA from my mother’s mother (Jane Garcia) at this region, further supporting the hypothesis that these matches are via my paternal grandfather.

I DID match the Zufelts on chromosome 7, however, and I can see that this region comes from my mother’s father (Theodore LaBounty):

Despite all of these matches, all of these trees, and the segment data, I could not place the Zufelt family within my maternal grandfather’s family tree. I hypothesize that the match is on Theodore’s mother’s side (Goldiah Blanchard’s line), as the other line is all French Canadian and usually very distinct.

What now? What do I do with this cluster to be able to tie it into my family tree?
Working with Unlinked Family Clusters
There is no magic tool when it comes to Unlinked Family Clusters. Sometimes a new match will come along and allow you to tie in the family. For example, if I found shared matches to the Blanchard family in the Zufelt cluster, that might suggest they tie in there. Or if I’m able to map the segments on chromosomes 1 or 7 to the Stevens family, that might suggest the Zufelts tie in there.
Often, however, we don’t yet have that new magic match and we can’t yet map the segment. So what can we do?
- Genealogy, genealogy, genealogy.
The single most important thing you can do with an Unlinked Family Cluster is to research the family and build out their descendants. Discover everything you can about the identified common ancestor or ancestral couple, and build out the tree forward. The goal here is to find a branch of the family that could conceivably tie into your known family. Hopefully you will get lucky and find a direct connection (for example, a great-grandchild married your great-grandfather).
Of course, it is possible that your link to the family is via an MPE (misattributed parentage event), in which case tree building may not directly lead to an answer. However, it will still help you locate the various branches of the family in time and space, which may be very beneficial as you continue the investigation.
- Work across companies
There’s no reason to limit a cluster to matches found within a single testing company. There are multiple ways to find relevant matches at other testing companies. The goal is to find as many matches to the cluster as possible, with the hope that new matches will reveal the unknown link to your family tree.
Let’s assume you’ve identified this cluster at company X, and you’ve identified the hypothesized common ancestor/couple of the cluster. You can search for this family among the trees of company Y (obvious, if the family is Johnson or Smith or a common family, this is going to be more complicated; however, you’re looking for a specific Johnson family so this method can work. It will just require more tree review and building). I found the Zufelt cluster at Ancestry, and I’ve found members of this Zufelt family at MyHeritage and Family Tree DNA. If you’re really lucky, you might even find some of the same test-takers from company X (in the known cluster) in company Y. You can then exploit this to use tools like shared matching to identify matches that are shared by you and that match.
If you’re working with segment data from company Y, you can look for matches that share that segment(s) at company X (remembering of course that overlap does not equal triangulation. See “A Triangulation Intervention“).
- Find the commonality
Researching the identified common ancestor or ancestral couple in great detail, and tracking the descendants forward, will also help you identify any commonality that could explain how you link to the family. For example, does a branch of the family end up in one of your ancestor’s towns or counties?
In my example, many descendant lines from the Zufelt ancestral couple end up in Upstate New York where my mother’s father’s family is from. If I didn’t already know that they tied into his ancestry at some point, this would be extremely helpful information.
- Walk back the cluster.
Jim Bartlett coined the phrase “walking back” to refer to pushing a segment or shared matching back one generation at a time. Here, walking back may refer to mapping the segment(s) back in generations to help identify the link between the known family and the Unlinked Family Cluster. For example, I’ve mapped back the Zufelt segments to my maternal grandfather, but that’s as far as I’ve gotten. If I can find a way to map the segments back further, I might be able to push that back another generation or two. Since I’ve tested my mother and several of her siblings, I could do Visual Phasing to possible push the segment back. Otherwise, I can continue to map matches as they come in (at 23andMe, Family Tree DNA, and MyHeritage) and hope that eventually I find matches with both the matching segments and the tree I need.
Similarly, I can walk back the shared match cluster by passive or active shared matching means. Passive means would be waiting for shared matches to show up on the cluster that provide a clue to the connection (for example, a descendant of a known line in my tree that is also a shared match to the Zufelt Unlinked Family Cluster). Active means would be testing descendants from different lines in hope of finding a new shared match to the cluster. This is, however, a bit of a gamble unless I have a reason to suspect a particular line (and even then it remains a big gamble as to whether they share any DNA with the Zufelt line).
- Examine the branches
Although I haven’t had much success with this approach, it’s a reasonable hypothesis that the line of descent with the closest matches, if statistically significant, could be the line of descent that ties into your ancestry. For example, let’s say that the Unlinked Family Cluster is the Snodgrass family and there are four grandchildren. The average shared cM for the descendants of grandchildren #1, 2, and 4 is about 20 cM. The average shared cM for the descendants of grandchild #3 is 40-50 cM. This might suggest that you are more closely related to this line and thus could focus your research on this line. However, it could just as easily be random chance that you and these descendants inherited a larger segment from the ancestral couple. So you might pursue this, but don’t put too much emphasis on this possibility.
Are these pile-up clusters?
A “pile-up” is a region of your DNA that statistically shares more matches in a database than is expected, usually due to old shared ancestry. Given the randomness of DNA and the randomness of who tests at any given database, we expect our matches to be evenly distributed along our chromosomes. However, there are huge spikes in matches, sometimes 10s or 100s of matches, that stick out like sore thumbs. Working with a match at this location can be problematic, as it likely to be a smaller segment/match and much older common ancestry (usually not identifiable due to spotty trees, poor records, etc.).
It is possible, therefore, that a cluster of shared matches (which VERY often form around a single segment or two, as with the Zufelt example) could be the result of a pile-up region rather than very recent shared ancestry. However, the fact that every match in my Zufelt cluster tracks back to the same Zufelt family suggests that rather than being a segment that is common within a population, this segment is more specific to Zufelt descendants and relatives and is therefore not just a pile-up region. Regardless, I will consider this possibility as I continue to search for a possible genealogical connection to the Unlinked Family Cluster.
Other Approaches?
What approaches have you found helpful as you work with an Unlinked Family Cluster?
ZUFELT. This comment is specific to Zufelt, so others reacting to the Unlinked Family Cluster may skip this. I thought I would put it here so you have my email, and not to clutter up the other discussion.
I not only have a larger cluster of Zufelt, but on chromosome 10; I also have two smaller ones (6 and 17) AND Y-DNA test that matches Zufelt — from a different surname. In fact, two different surnames at this point, suddenly got another match, from yep, Schoharie County/upstate NY. Plus more of the surname I work on in the autosomal clusters from more distant cousins.
I have my own Excel spreadsheets on the problem. I have a cluster of at least 22 Zufelts on 10 from 14-65 cM, descended from either Adam + Neeltje or Johann Michael who was married to his first cousin once removed Catharina Shufelt. (I was able to test my husband’s uncle before he passed so have some larger amounts.) Both Adam and Johann Michael are supposed to be sons of Johann Wilhelm, son of the Palatine patriarch, Johann Georg. Catherine is supposed to be a granddaughter of Johann Georg’s son Georg Adam.
Having exchanged email with some of the Zufelt researchers, I know the genealogies are kind of a mucky mess with this early period in the Hudson River valley.
Of course, this is frustrating; I feel that my guy changed his name to something much less ethnic, as did perhaps the other Y-DNA match that wasn’t a Zufelt. There is already some legend about the name change.
I also have a small Zufelt cluster related to Canada and upstate New York.
Some show as Maternal and others as Paternal. I came across the Zufelt’s when I was working another larger cluster of matches related to Backstead’s,. That cluster turns out to be a family out of Canada that migrated to Utah with original Mormon settlers. One of them had 3 wives and 31 kids. I have numerous matches from his descendants.
My half sister also has a cluster of DNA matches to people named Zufelt (1) or with Zufelt names in their tree (21). Ten are marked Paternal, which would be her father’s line going to NY, some of them were in the Hudson Valley in the 1700s from Germany. The rest are marked Maternal (10) or Unassigned (1). Maternal matches should be early colonial New England from England. I have not explored these in depth at all. When I looked at the top shared matches, they are all 40 cMs or under, and none of them connect to the much closer matches she has so I don’t have a theory about where they might come from. My sister Marilyn Cramer , who died 2 years ago today, was an expert on the Hudson Valley area of NY so I can’t ask her who they might be. All of her NY research has gone to a cousin there.
I’m so glad I’m not the only one who has these! I have several! I am able to build large diagrams (just like your lucidchart above) and by searching among my match list for the surname (or spouse’s surname) I’m able to find more and more matches that link into the tree. The hard part is the descendancy research! Often there are so many matches because of large numbers of children among the ancestors. It’s very time consuming, but thrilling when you finally find a link!
Thought for you: if you use a tool to view the trees as 3D directed graphs, and draw lines to mark the gene inheritances supported by evidence and probability, would that better help visualize the most likely possibilities?
What’s the possibility of two branches having a child, thus mucking up your probabilities, and that child then taken in elsewhere? You should be able to identify branches that are more or less likely to have joined for this. For example, if two branches are both missing one or more of the shared genes you’re looking for, that combination would be low probability.
Please see my most recent blogpost at http://www.Segmentology.org – if you can get cooperation with a distant Match (invited to their Ancestry kit), you can look at their Matches (ThruLines would make this easier) and see what percentage of them are also DNA Matches to you. This might indicate the number of generations back to the Common Ancestor. And thanks for the Hat-Tip.
I agree. I’ve used many a more distant match’s access to DNA to triangulate trees / see different ThruLines DNA matches / find common locations that overlap with mine. It’s really been helpful (GEDmatch does this too, but Ancestry has the bigger database and has already split them into (for the most part) accurate sides).
Being invited to access the kit of a remote match is the ideal situation, but so often I can get even get a response to a message. So I’m really enjoying the Ancestry ProTools view of shared matches – showing the likely relationships between the shared matches. And it’s including more remote matches, although care is needed because it can include matches that are related through other paths. You can especially see this when you start looking at a match on your maternal side, move from match to match and then find your looking at paternal matches. As Blaine has said, doing the genealogy work on these matches is essential, but it’s a great way to extend the unlinked cluster and at least a few of the matches together.
I’ve found it helpful to increase the coverage for the side of the family where I think the unlinked cluster is from. Maybe testing more of your mom’s 1C, 2C, and 3C could help.
Yes, I have a large cluster of over 70 matches who share DNA with my Dad, his granddaughter (my niece) and five of his second cousins! From the clusters’ trees on Ancestry, I traced their common ancestor to Stephen Garlick and 3 of his sons, David Adam and Jacob. One of David’s daughters married 3 times and another twice – descendants are the closest matches, but come from all five marriages. Picking up on Linda’s comment about your Zufelt cluster, Stephen’s ancestors came to the US from the German Palatine in the early 1700s (name then GERLACH) and settled in the same area – New Jersey/New York and Pennsylvania. Their family legends say that Stephen’s mother, and one grandmother were Mohawk women. On our family side, the cousin matches indicate that the connection should be through Dad’s great-grandmother from rural Sussex, England, as there are no matches to her husband’s family, or other great-grandparents. I have used Excel spreadsheets to try and sort through the matches. I built it upwards from the DNA matches with trees on Ancestry, and put that tree side by side with our Sussex ancestors. By the early 1700s, I ran out of parish records with no obvious connection. Next, I am trying to build down those family lines to see if anyone disappears (to America?) or otherwise connects to the Garlick cluster.
I have 4 of these clusters and have worked them in pretty much the same way and I’m in the same boat – working them as much as I can while waiting for that elusive match to tie it all together. Process of elimination as above indicates 2 are paternal, but as I have 6-7 generations of solid DNA connections on most of those lines which include 4-5 in Australia, and the clusters have very well researched trees back to colonial US, I am stumped. To top it off, it’s one of the 5 most common US surnames: Jones! Unfortunately, my father passed young and only had one sibling (tested), so I am heavily reliant on an extra generation of diluted DNA.
I had one of these and it was driving me crazy. A whole pile of matches from the US with the same surname that wasn’t in my tree and no other connection to the US.
I managed to solve it by using the Leeds method. All the matches were descended from one woman who lived in the same small village in the UK as my g-g-g-grandparents. This woman’s father was a brick burner and my g-g-g-grandfather was a brickmaker so highly likely they worked together and the families knew each other. Looks like my g-g-g-granddad fathered her.
Hi Blaine. I have been waiting for this article with great anticipation!
I came across my first Bettinger Cluster of unknown matches that tied to my great-great grandfather, which was exciting as I have worked with several other descendants of him for 20 years trying to determine his parents. And then it wasn’t so exciting as this cluster tree began to grow and I could find no connection. After a couple years, I found the answer. My great-great grandfather was the illegitimate child of Thomas Cochran in the cluster tree. Looking back now that I have the answer, I wonder… Although my cluster tree went back a further generation to Thomas’ supposed father (I had matches to all his siblings) I had far more matches to Thomas than I had to his siblings. Was this telling me something? It’s not quite what you did with your analysis of average shared cM for each line – as you pointed out, at this distance that’s not necessarily a useful analysis. But I would expect to have more matches to Thomas than I would have to his siblings simply because the sibling matches connect to me a further generation out.
I ask because I have two more of these clusters that are tied to Thomas, who may help identify his unnamed mother. (These are matches related to my Cochran matches, but who do not have Cochrans in their tree.) Am wondering if that same pattern might come into play, i.e., concentrate my searches on who is identified with the most matches. But I am dancing on the edge of the limits of what we’re told autosomal DNA can help identify, as this is now looking to identify 5G grandparents (who would have parented my 4G grandmother, who would have been the mother of my 3G grandfather Thomas.) I’d love to hear your thoughts.
Trish
I have one of these clusters, tracing back to a Quaker couple born about 1660. Based on geography (small region of Baltimore County, Maryland) and surnames, I’ve nearly made a connection to one of my brick walls, my 5G grandmother, born about 1800, but there’s a gap of a generation and so far I haven’t found a paper trail to support the connection. The generation before that appears to have left the Quakers and the excellent paper trail dried up! Still working on it, using all of the approaches you listed above. I’ve also been using DNAPainter’s WATO feature as a way to make quick trees to track this and other unconnected clusters. (Not using it for WATO calculations, just a way to visualize the cluster, similar to how you’re using LucidChart.)
What’s interesting to me is that the pattern of matches I see in this cluster supports the idea that I’m tracing a single segment with a 50:50 chance of being passed on in each generation. One of the sons of the ancestral couple of the cluster had about 11 children, and I have matches in the cluster to descendants of 5 of those children but not the others. One of those children also had about 10 children, and again I have matches to descendants of about half of them. I also think these large early colonial families make it more likely that a segment will “survive” in a large number of descendants, potentially leading to large clusters.
Thanks for another very thoughtful and thorough explanation. I also have clusters like this, only one of which I have explored this extensively. My steps very much mirror what you have described, but I could never express it so clearly. I one approach that has solved a number of smaller and somewhat less challenging mystery clusters was using the segment search tool at Gedmatch, researching each triangulating match sharing the same segment, You mentioned this a little bit, but for me, the expanding group of attached Gedcoms and Wikitrees, combined with backtracking the match to the original database and tree, has yielded some great breakthroughs.
Many thanks for this post. I have a similar cluster on my father’s side that is doubly problematic because it overlaps with the well-known pile-up regions near the beginning of chromosome 15. Many of my matches there share large segments with me (up to 42 cM) and many of them descend from a family named Gilbert in Somerset, England, where many of my father’s ancestors lived for generations. The trouble is that these Gilberts were among the earliest emigrants from England to the US. I’d love to know whether you or others think that I’m wasting my time, given the known pile-up area, or whether I might really have Gilbert ancestors in Somerset in a genealogical time frame.
Great post on a great issue.
Have been chasing several of these over the past 5 years.
Obstacles: matches only testing at Ancestry and without much of a tree; ditto for 23 and no tree at all; lack of geographical/regional information in trees; mistaken information in trees taken from other sources who were wrong, or family deliberate misinformation; lack of dates: “Freda Bloggs, deceased” is a frequent entry type, with no other information and Bloggs is a married name.
Successes: Finding another branch confirming the initial couple common to matches, then another pointing to just one of those partners, so moving back another generation, and tying the furthest up the line to a specific region – GEOGRAPHY is key! Dates help too. Occupations if available can also be great distinguishing factors.
Finding all fingers pointing to four unmarried brothers in the same town. I still don’t know which was the unacknowledged father, but I know for certain their parents are the Connecting Ancestors.
Pending: The CAs appear way back, and any match back then will be <20 cM so Shared Matches might be a problem. So far only 6-10 matches, but solid ones. I just need one or two back another generation to improve the situation.
All tools are required, but back 5-8 generation where these lie for me, segments are becoming more and more important. GEOGRAPHY, and knowing local history – when mines closed and new ones opened elsewhere, and who else in the family might have made that trip a little earlier and served as a pathfinder.
Finding that stray copy of a will that just happens to mention a key person.
Going the extra mile with name variations, looking at yet one more transcript of the same document to see if there was one scrap more of information, working the witnesses to events to see if they might fit in a possible tree.
Sleeping on things. Talking to a fellow genealogist who knows the area and time.
Being courageous enough to say to a match, "I know your tree says one thing, but I seem to be getting a lot of Shared Matches that suggest another scenario. Are you seeing the same thing?"
And good luck to all. It can be very hard but also very rewarding.
Hi Blaine,
Thank you for a very interesting article. I am working entirely with endogamy, but nonetheless think finding significantly sized groups of matches that track to a common ancestor may one day be useful to me.
…just wanted to point out a tiny blooper in your concluding sentence–you referred to the group as “unliked” rather than “unlinked”!
Haha, sometimes they ARE unliked!
My largest cluster is from an unknown ancestor in Maryland. I have been able to trace most of these matches to the Ford, Price and Barney families of early Baltimore. I’ve given up this research because there simply are no documents. I feel no satisfaction “knowing” these ancestors are behind my brick wall because I can’t make the connection.
I don’t know if this qualifies as the kind of cluster you’re talking about. About seven years ago I was contacted on Ancestry by someone with a 157 cM match. I’ll call him A. A had been adopted, and at the time he signed up for Ancestry only a half dozen people matched him at more than 100 cMs. One of them had the same surname as my maiden name (H) matched him at 200 cMs. Before we “met” she had told him that because she had the highest number of cMs except for two other adopted people, then he must be a direct descendent of our H family. She was so convinced of this, that she even provided him with the names of several of her own male cousins that might qualify as his father. So for seven years, A and I worked to see how he fit into the H family within the assumption that the names provided by the 200 match were true possibilities. was 13 when A was born. Another was 50. We know now that his mother gave birth to him in her 20’s.
After all this time there suddenly appeared on Ancestry a cousin match for the A at the 1150 level. I will call it “S”. Within a few weeks several people of the S family were tested and before A knew it he had found his maternal family and even had DNA proof of a half sister. Also, around this time several other cousins popped up in the range of 600 to 700, all of whom had surnames, well known and related to the S family. Suddenly everything we thought we knew was tipped on its head and the 200 match and my paltry 157 match paled by comparison to the strong matches in the new S family.
The only problem was, none of them lived within 1,000 miles of A’s supposed father.
Another surprise. This S family also turned out to have 150 cMs with both me and the other 200 cM person matching A. So this S family that I never heard of turned out to be 2nd-3rd cousins to me, the 200 match, and A. And, back at the 5th GParent level we all had a common ancestor. Not very helpful because every time we try to figure out the connection between the S and H families, up comes the 17th century common ancestor which doesn’t explain the 2nd-3rd cousin DNA match. So while it’s not actually a separate cluster, it doesn’t get us closer to identifying A’s father.
A’s family tree looks like a capital C. It curves up through the S family to someone who lived 300 years ago and comes back down and stops, unable to connect his unidentifiable father’s side.
I’ve tried going up S’s tree and down the H tree to see where they can cross to make the S family my 2nd cousins. Just can’t connect them.
So, I recently went through this process with a cluster. This cluster includes a small cluster of Zufelt matches.
I saw a cluster of people with the name Beckstead that seemed to be based in Canada and New York. I actually made a fairly large cluster of the family with a number DNA matches. Also, in doing research it turns out a number of the family members migrated with the original Mormon Utah settlers. This includes some family members that 3 wives and 31 kids once they settled in Utah.
Also, I don’t necessarily trust Ancestry’s identifying paternal vs maternal matches. This particular cluster I have matches that paternal and when I look at share matches they say maternal.
My father has a grandmother from place B. His other 3 grandparents are all from place T, with much endogamy. So all his B relatives form one DNA group and his T relatives form another group that cannot be broken down using DNA alone.
Ancestry has deemed his B relatives as paternal and his T relatives as maternal. Which is understandable if just looking at the DNA patterns, but incorrect.
I also have a cluster with the Becksteads that I cannot figure out at all. They did live in areas where my known family is from, though, so there’s got to be a link that makes sense. I keep shelving it for a while, hoping more information will present itself later that maybe hasn’t been digitized yet.
This is so timely for me.
I’ve been wracking my brains over the Thomasson-Pollard family that appears consistently on my paternal grandmother’s side but doesn’t link clearly with anyone. They’ve lived in locations near my identified lines, but never directly married in. I suspect that there is an MPE in there, and am trying to narrow down the connection. But for now, I can only map it up and down.
Hi Erica, we have Thomasson-Pollards, too!
Thanks for writing about this topic! My father first tested at 3 major sites, then more recently at Ancestry. At 23andMe, ftdna and My Heritage the close shared matches lined up nicely and fit into categories according to family branch. However when Dad joined Ancestry there was a family who were fairly close matches – we just had no idea who they were! By a process of elimination we could work out who they weren’t, and that was useful. It turns out they were ‘standing’ where our Walker folk should be. I now think that in the other sites I had attributed Walker because the great-great-grandmother of the marriage was represented in dna matches but not necessarily her husband. As one commenter has said – be prepared to have everything flipped on it’s head in terms of what you think you know 🙂 And yes, geography is important too. Although both families emigrated I think an npe event occurred in a small town in Scotland. A married woman and a much older man is what seems to be the scenario, and that skews the generational alignment.
I have one of those! a small family in yorkshire, consisting of mother, father, an unmarried daughter, and a married daughter and her husband immigrated to Utah as LDS pioneers. their surname was clarkson. one of their descendants has a good match to my paternal side, the Clarksons, matching me and my brother. They are also a match with a couple of my male cousins. try though I have, over the last 8 years, I have not found the ‘link’. I live in hope…
I only see one thing wrong with this chart. It should say grand aunt/grand uncle where it says great aunt/great uncle and great aunt/great uncle where it says GG, and so forth.
I have had great success using cluster mapping software along with the Ancestry database to solve my unlinked family clusters. In fact it was the cluster mapping software which initially identified these large, previously unknown groups of unlinked family clusters. In every case, solving a cluster, and linking it to my pedigree, required building out my tree to 8th, 9th and sometimes 10th great grandparents, using DNA matches and triangulation, but often WITHOUT a documented paper trail. I might add that I do have fairly extensive endogamy which may have helped me to extend my pedigree. I am currently working on using VISUAL PHASING to determine from exactly which grandparent these unlinked family clusters descend.
I have identified and then built corrected, documented trees using only primary data for 6 Ancestry matches at the 17 to 21cM level all with the same common surname. As background, these are all on the paternal side since my parents come from different population pools. I’ve been successful in working back to their various male ancestors born ca 1800s. Each of these men is located in NW Tipperary and eastern Clare, two in very small villages known to be ‘my’ family’s tiny villages based on contemporaneous, primary family data.
The no. of generations from the test taker to the EKA is 6. Y matches of male relatives confirm the geographic area and the surname.
Am I just picking up very old population segments and should forget to try to knit this side together? Seems unlikely there would be this many men with such similar cMs, but surely I’m missing something.
What tools would you suggest I use to untangle these guys? I’ve been unsuccessful coaxing folks to upload to gedmatch.
Thanks all for this great discussion!
here https://thegeneticgenealogist.com/2022/08/07/an-in-depth-analysis-of-the-use-of-small-segments-as-genealogical-evidence/ wrote some similar
This problem has plagued me from the start. I called them “island matches” since they were matches that matched each other but there was seemingly no link to me or even each other. I’d say a great number of my matches fall into this catagory.
If you’re able to find out how these matches relate to each other then consider yourself lucky. So many users have no trees or trees with only living relatives that are private by default and do not respond to requests, frustraiting any attempts to solve the issue. I suspected that pile up might be one cause of this but I belive Timber accounts for this. I imagine the most likeliest possibility is distant NPE’s. If your 3rd great-grandfather had a child no one knew about then you’re going to have some half 4c or half 3c1r out there that are going to be a nightmare to ID
So relieved to know it’s not just me :-). I have, depending on how you look at it, two or four of these. One has a couple of people who share a 2C on my paternal grandfather’s side, so at least that’s a hint. The other “one” is a group of three ancestral couples whose offspring have a lot of ICW, and in one case a triangulated match between descendants of two couples.
If anyone wants to play along, the ancestral couples I’ve traced the biggest cluster to are: Alexander Marion Green (1835-1895) & Mary Jane Summers (1836-1920) from Illinois, Warren William Conklin (1852-1930) & Ida Augusta Darling (1860-1948) from Suffolk County, New York, and William Henry Dutcher (1856-1894) & Flora A. Collin (1859-1890) from , Berkshire County, Mass. My ancestors on the branches most likely to connect were mostly from Pennsylvania and Western New York State (about as far from Suffolk as you can get and still be in New York). So much fun! 🙂
How necessary is it that “unlinked family clusters” be comprised of 25 or more matches? I’ve found several of these clusters with only 6-10 shared matches. The matches meet all the other 5 characteristics of the definition mentioned above, and these matches descend through several child lines the common ancestor/couple.
What if you have a cluster and can’t identify the common ancestor/s?
In ancestry, my 2nd biggest cluster and 23andMe my 3rd biggest cluster have roughly the same people in it. This is my paternal line. I have contact with some of the matches and we cannot work out where our tree intersects. Most triangulate on the same segment of Chr 5. What do I do next?
I have at least two of these clusters. The one I have done the most work on is the Dougherty/Daugherty group which my sister also shares and is on our paternal line with its very long generations. The group is now over 100 matches; everyone with at least a few people in their tree is being built into my tree using Legacy. People with this name emigrated to America in the 1720s. My connection must be before then seeing I have no American ancestors. I have guessed it is probably through my great grandmother Hannah Lockhart born 1831 in Castleblayney to Robert Lockhart and Hannah Ligate/Liggett. I have no details of their families except guesses through DNA matches.
I have one of these in my research! I am so glad to read your article about this.
I have at least 12 triangulated matches on MH, that relate back to a couple. While a few others relate to a different couple with the same male last name in the same geo area. Perhaps tree errors? Ancestry info says these matches are on my fathers line. My paternal 3 G grandfather is unknown, oral history and brith docs show that this is accurate, so i was hoping this might shed light on who my father’s father’s people are.
I have another 14 matches in this cluster at Ancestry. Over all there are over 50 people matching in this cluster, which also looks like pedigree collapse in the MH produced cluster.! Only one Ancestry match is in Scotland, 55 cM, 59 unweighted. MH says MRCA for the closest MH match 49 cM should be 3 Gg grandparents. But all these matches are in the USA, and all my ancestors are in Scotland.
Am i missing an uncle that went to America.? All the ancestors in the unlinked cluster trees that have made have been in the US since at least the mid 1700s. My ancestors were all domestic servants and farm labouers so it doubtful they would have travelled to the US for a visit. I am at a loss where to look next.
Thanks for detailing something we’re running into with more frequency …and explaining why..also I am a 5th gtgrandaughter of Adam Zufelt and Nellie🤪
I have a very large Unlinked Family Cluster on my paternal MacLeod line leading to the Isle of Raasay in Scotland. I’ve built the trees of over 1000 atDNA matches back to Raasay without finding a common ancestor. Raasay is a small island near Skye and is perhaps a textbook case for endogamy. I tested 5 MacLeods living on Raasay (atDNA) and have the shared atDNA results of more than 50 people with Raasay ancestry, including 12 family members. The Raasay folk are related to one another in more than one way (in one case 7 different ways), with highly elevated cM match levels to each other and my family (in 1841, 35% of the population were MacLeods). There are about 20 Raasay MacLeods with Big Y DNA test results and while we share a common ancestor b.c. 1300, they are still atDNA matches to my family. (Y-DNA from three 4th cousins supports our genealogy with a common ancestor b.c. 1785.) My conclusion is that centuries of intermarriage has completely confused atDNA leading to misleading matches and rabbit trails. I believe we have multiple common ancestors with these matches before the time of paper records.
I have a large number of unlinked clusters. In nearly all cases, Ancestry identifies my matches as 1/2 3C1xR, which puts the ancestral match somewhere around 1870-1880. Each seems to have a locus somewhere in upstate NY. I have built out trees for two of these clusters and am working on a third.
I also have a known male ancestor, call him Charles, whose parents entered a poorhouse in that time frame, listed as paupers and alcoholics, and Charles is in the 1870 census age 15 as a laborer on a farm near the small community where the first cluster is centered. The two other cluster I am working with are centered in the Rochester area, but they all appear to tie back to Charles. In 1880 he had moved to Washington.
My current hypothesis is that he was a serial rapist who finally had to flee. Although this happened 150 years ago, there appears, in several cases, to be ramifications that flowed down to more recent generations.
I know these do not affect my direct ancestry, but I am a nerd and continue to try to resolve these. I am not sure how to approach other matches in these clusters to share information and to suggest that they send their DNA to GEDMatch for better comparison. I, perhaps irrationally, also feel that an apology is owed these matches. Advice is welcome! Thanks.
I have had my dna taken with Ancestry and have an extensive tree. I do get confused with all the names (Groote) is connected to Liz ancestors in my tree. She may look it up.
Lona
I’ve been working on a cluster of over 200 people now for years on my Dad’s side of the family. They all trace back to a few Quaker couples as far back as the late 1600s. This group started in Pennsylvania, moved to North Carolina but didn’t stick around long before migrating on to Ohio. One problem? They moved to an area where my Mom’s family came from, so I get both maternal AND paternal links among the DNA matches in that cluster.
I saved the most interesting for last: my Dad is descended from Chinese immigrants who went to South America and intermarried among black slaves from Barbados. There is a tiny tiny bit of white ancestry on my Dad’s side and it apparently traces back to these Quakers. So one problem is trying to get paperwork on 18th and 19th century black slaves in Barbados. My quandary is figuring out how a Quaker from PA or NC ended up fathering children by black slaves in the Caribbean. I’ve so far found no evidence of the Quakers in this cluster owning slaves. But… their DNA had to get to Barbados somehow.
For now, I’m just leaving some blank spaces between my main family tree and this cluster. I know it’s there, I just lack names, places, and dates. You know, evidence.
I have a large cluster of DNA matches (over 115 that I’ve identified into a group, but probably many more) from South Carolina on my maternal line of both Western European (like me) and African descent. Many of their trees have the surname Gaillard, and they all have deep SC roots. It seems likely the Black relations are a result of slavery. I built out a tree for them, but I can’t figure out how they connect to my family. It’s such a large cluster that “Early South Carolina African Americans” is one of two of my mom’s Ancestry DNA Journeys, despite her not having any African DNA.
The oddest thing is that the only ancestors we know of who lived in South Carolina were my 6x-great-grandparents… the family moved to Virginia after that, and there’s where they then lived for several generations. The closest match shares 113 cM with my mom and most of the matches predict 2nd to 3rd cousin relation, so wouldn’t the shared ancestor have to be closer than 6 gg? Given all this, it seems maybe one of my ancestors secretly fathered a child. I don’t know how I’ll ever be able to solve the mystery if none of it was recorded and no one knows the truth, but I sure hope I figure it out someday.
This was a fascinating read. The concept of an Unlinked Family Cluster perfectly describes a situation I have encountered in my own DNA research. I have several matches who clearly connect to the same ancestral family, yet despite building trees and reviewing shared matches, I still cannot determine where they fit into my known family lines.
I especially appreciated the emphasis on genealogy research rather than relying solely on DNA tools. Your example of the Zufelt cluster shows how much patience and detailed tree-building are often required before a breakthrough occurs. It was also interesting to see how you combined evidence from multiple testing companies to strengthen the analysis.
Articles like this are a great reminder that not every DNA mystery has an immediate answer, but careful documentation and continued research can eventually reveal connections that seem impossible at first. Thank you for sharing such a detailed and practical case study.
Hi, I’m Camp Devid.
This is one of the best explanations I’ve read about Unlinked Family Clusters in genetic genealogy. I’ve encountered similar situations many times while researching DNA matches, where a well-defined group of 20–50+ matches clearly points to the same ancestral family, yet none of them fit anywhere in my documented pedigree.
One thing I completely agree with is that there is no shortcut. When a cluster refuses to connect, the answer is almost always genealogy before genetics. Building descendant trees, studying migration patterns, researching collateral relatives, and comparing records across multiple DNA platforms often reveal clues that shared cM values alone cannot.
I also appreciate the emphasis on working across different testing companies. I’ve solved several difficult DNA puzzles only after combining evidence from Ancestry, MyHeritage, FamilyTreeDNA, and chromosome mapping. Every new tester has the potential to become the missing link that finally connects an “unlinked” cluster.
The Zufelt case is a great reminder that patience is essential in genetic genealogy. Sometimes a mystery remains unsolved for years until one new match or one newly discovered record changes everything. That’s why I never delete or ignore these clusters—I document them carefully and revisit them as new evidence appears.
Thanks for sharing such a detailed and practical article. It reinforces an important lesson for every genealogist: DNA provides the clues, but thorough genealogical research is what ultimately solves the mystery.
Excellent explanation of the Unlinked Family Cluster concept. I’ve encountered similar DNA clusters where dozens of matches trace back to the same ancestral couple, yet the connection to my tree remains unknown. Your emphasis on thorough genealogy research instead of relying only on DNA tools is a valuable reminder. Thanks for sharing this detailed case study.