Today, I saw an interesting table posted to Facebook, summarizing a genealogist’s family tree. It listed a handful of generations along with the number of possible ancestors in each generation, and the individual’s known ancestors for that generation.
Out of curiosity, I generated a similar table with my own data:
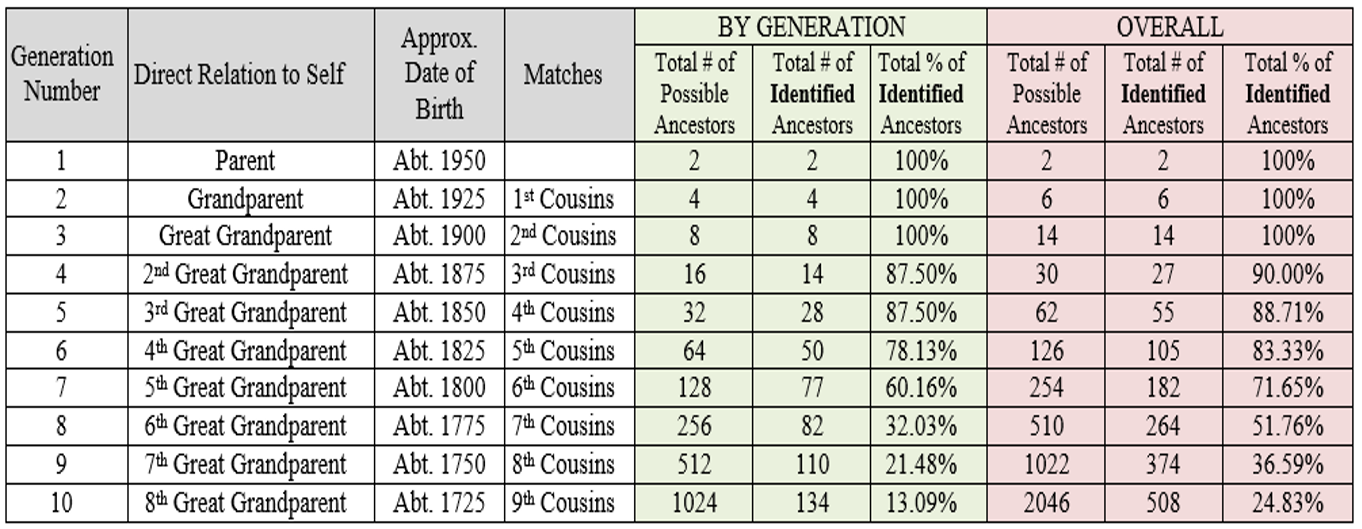
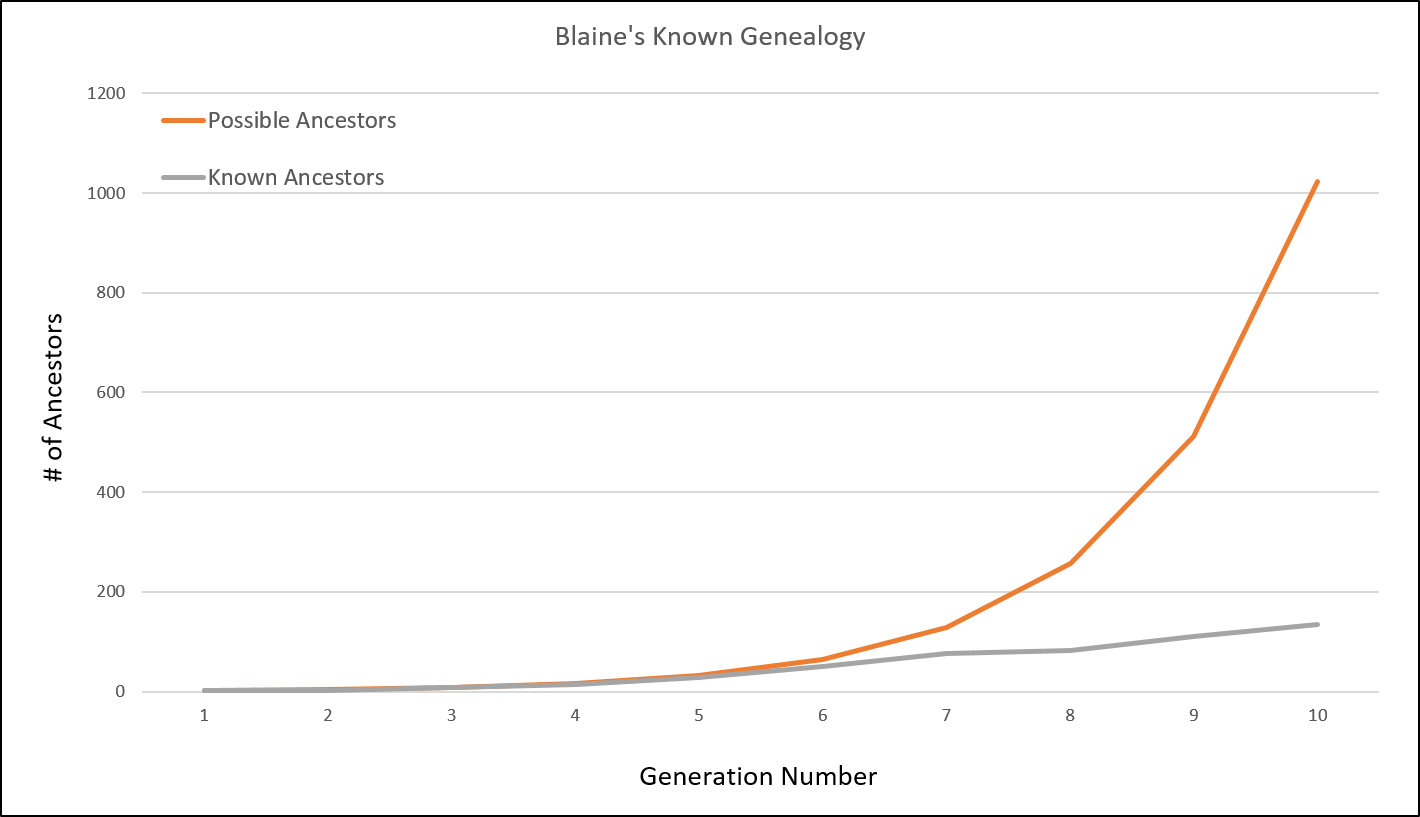
There are many interesting data points in the table. For instance, between the 7th and 8th generations, I drop from knowing 71% of all of my ancestors to knowing just 51% of my ancestors. At 10 generations, with 2046 total ancestors in all generations, I only know a quarter of them. And while I feel very confident for the first 6 or 7 generations; after that I’m much less confident with my family tree.
So this is an interesting exercise, but is a table like this at all applicable to genetic genealogy?
The Importance of Knowing Your Family Tree
Having a chart like this for your own family tree, or at least some knowledge of the information in such a chart, is a vital consideration in one’s determination of confidence in a conclusion made using DNA.
I recently stated the following in a thread in the ISOGG Facebook group:
“No atDNA paper or proof argument should EVER make a conclusion based on shared segments without at least a sentence or two about the lack of known overlap in other family lines. Or, alternatively, addressing known overlap. That is a fatal error.”
My point was that whenever we make a conclusion about a particular ancestor or ancestral couple based on segments of DNA shared with a relative, we absolutely must address whether we do, or could, share other ancestors with that relative.
For example, when I’m reviewing someone’s conclusion, I need to know whether they’ve at least considered the possibility that they could share DNA from another line instead of or in addition to the line on which they’ve focused. I need that information to evaluate their conclusions.
Now, maybe I’ll go one step further. Perhaps I’d also like to see how likely it is that they might share DNA via more than one recent line of their family tree; one vital factor in that probability determination is the extent to which they and their match have researched their family tree. And this is the topic I’d like to get other people’s thoughts on.
Of course there are many caveats, but ultimately they don’t really change my question. For example, we all know that family trees are notoriously error prone and can be subject to misattributed parentage. As a result, even the most complete family tree can be misleading. Or maybe your family lines are so diverse that you can be fairly certain there’s no unknown overlap affecting your conclusion. In either case, providing that information will help others evaluate your conclusions.
I know what some of you are thinking right now: “I’m not going to publish my conclusions anyway.” Or perhaps: “It doesn’t matter what others think of my conclusions.” Maybe you aren’t writing for a publication, and maybe you’re doing this for yourself, but ultimately your genealogical conclusions will be judged and evaluated. Whether it’s a relative that we decide to share it with, or a relative going through our files after we’re gone, all of our conclusions are ultimately evaluated.
An Example
Let’s use a quick example.
Joe, Julie, and John are all predicted to be about 5th cousins with each other (although I use 3 cousins, it could be 4 or 5, or even more). They all share a 22 cM segment of DNA on chromosome 3 which they’ve triangulated to a shared 4th great-grandparent, George and Susan (Gold) Silber. The triangulation of the segment of DNA is a definite plus, and it looks like a good conclusion.
But let’s factor in their family trees:
- Joe: an experienced genealogist, John knows 85% of his family tree out to the 6th generation
- Julie: an intermediate genealogist, Julie knows about 45% of her family tree out to the 6th generation
- John: a beginning genealogist, John knows about 10% of his family tree out to the 6th generation
How confident do you feel about their conclusion now? Julie is missing 55% of her family tree and John is missing 90% of his family tree. Doesn’t that increase the likelihood that their shared ancestor could be located within an unknown area of their family trees?
Is this information we should have when we evaluate a genealogical hypothesis or conclusion using DNA?
Questions
Does this example suggest that beginning genealogists shouldn’t make conclusions using DNA? Of course not! Does this example suggest that we need to ignore any conclusion unless you have 100% of your tree completed? Of course not!
Does this suggest that everyone should create and share a chart like the one I’ve provided when they want others to evaluate their genetic genealogy conclusion? Perhaps, yes. I can say that it only took about 30 minutes for me to create these graphs, so the burden is extremely low (especially when compared to the hundreds of hours spent on DNA!) and the return on investment is extremely high.
So what are your thoughts on the matter?
.
My thoughts are that some terminology needs to be defined:
1) By “family tree” you’re really referring to direct line ancestors, not the myriad of cousins, aunts, uncles and the rest that a person may have documented.
2) How is a “known” ancestor defined? You have a name? You have genealogically acceptable proof/evidence or only family stories?
Those are EXCELLENT questions Bonnie, and exactly the types of things we should be thinking about. I’m not sure there’s a right or wrong answer, but here are my thoughts:
1. Yes, “family tree” as I used it above referred to ancestors only (as all genetic matches will track back to ancestors)
2. For me, I used “known” when I had a name; I did not require any substantial evidence. This means that “name collectors” will have inflated percentages, for example. On the other hand, requiring substantial evidence will significantly lower my percentages. Perhaps there’s a balance.
Thanks for the great questions!
For 1), the chart does a good job of reminding us of the many, many people who contributed to one’s life.
For 2), name is a good start. Say, Torrey’s mentioning a person (he always showed a source). In some VR, there might be the parent’s names for a birth (see sourced ahnentafel, below, in my comment). In the next generation, if there is nothing more, then we lose two in the count for that generation.
In regard to balance, a weighted sum would do that. Having “name” only would be lowly graded. And, so forth, all the way up to what being the strongest?
I need a name and a location. Location can be huge factor when trying to figure out whether there is any possibility of a match.
— I need to know whether they’ve at least considered the possibility that they could share DNA from another line instead of or in addition to the line on which they’ve focused. I need that information to evaluate their conclusions.—
This is my issue. Now that I’ve confirmed my 1/2 3C1R shares a large 50cM largest segment with my mother, given my situation as you know, I have to wonder how many other lines do we share on that since another person shares on that same exact segment, yet his ancestors do not come from the same place as mine, at least not that recently. So although that large segment may lead up to that particular ancestor that we share in common, I have to wonder is that whom we got our segment from? I am in the process of getting a confirmed 4th cousin also who is also a 1/2 3C1R to the one my mother shares 50cM (largest segment) to see if we do match at that same segment, or not.
Kalani – I agree completely! Even a statement about very different backgrounds might suffice in some situations (although based on my post I think the burden should probably be higher, and possibly quantitative). For example, it could be something like this:
“Cousin B and I appear to have very different backgrounds; my known background is exclusively European, and Cousin B’s known background is mostly Asian with one known European line.”
Not perfect, but at least it’s something.
Great post on Ancestry but I think most Asian countries are not well informed on this topic. If only we could education the Asiatic population on this issue as there are many migrants settling down and creating their roots all over Asia. Website such as Ancestry.com only target Eu and Australia but none from Asia.
To say it is important is a understatement for my family. My husband was adopted by is step father,his biological father was adopted by his stepfather. Breaking down those walls to find five generations have died of stomach cancer. So having my husband tested he was in the early stages of stomach cancer. He will be the only one to survive it. Looking ahead it’s a genetic cancer CDH1 mutation gene. Tested three of our children and sadly our daughter has it,but she is aware of it and having testing. Genealogy has saved our family.
Vickie, that’s a striking example of how genetic genealogy can have vital implications. It’s possible that you would be able to help identify collateral relatives at risk for the same condition. You can write to me directly DNACousins@gmail.com if you’d like to discuss this further.
I enjoyed your post Blaine. I’m new to this and wanted to ask, what is the correspondence between predicted MRCA and the generations? I also have a similar pattern of knowing some but not all after the 6-7th generation, and also find that there is pedigree collapse where two of my GGPs are siblings (one female- 5th GGP, one male- 4th GGP; their parents are listed as 5th GGP) How might those connections affect the percentages of MRCA? Mil gracias, Ellen
Blaine, A great analysis and post. I have a similar chart on a 3×5 card that I carry with me as I make DNA presentations. My point for all genetic genealogists is that the weakest link in our quest, is our puny Trees! My estimate is that the sweet spot for atDNA Matches is 6-8th cousins – that’s where the bulk of our Matches lie. Let’s take the 7th cousin level (256 6G grandparents, 8 gen back) – even with pretty good Trees, most genealogists may have 50% of their ancestors identified, or 1/2. With a Match who also has 1/2 identified, we’d only find a Common Ancestor maybe 1/4 of the time. And this is considering one of the very best outcomes. The point is that our Trees are the limiting factor, not the atDNA, IBS, miss-calls, etc. And that’s presuming this 7th cousin match will reply to your email/message (subtract another 50% or more), or even has a Tree of any merit (subtract another 75% or so). By the time you factor in all the issues, there’s slim pick’ns… So my constant harangue is: genetic genealogists need robust Trees (as many ancestors as possible; and I’m now adding children of ancestors, because so many of my matches cannot work their TN, KY, MO ancestors back to VA, etc. )
And I concur with your thoughts on an ancestral Tree – it’s most important to get the names in there; it’s next important to add bmd places and dates. If the Common Ancestor names are not in the Trees of both you and your Match, the difficulty level (in finding a CA) goes way up. Matches from a Triangulated Group are very helpful – often more than one of them will reply, share and help determine the CA, and/or provide place/time clues.
Our main issue is highlighted in your chart – genetic genealogists need to fill their Trees with as many Ancestors as they can – out to 12 or 13 generations wherever possible. “Sticky segments” will come down from some of those ancestors.
Thanks, again, for highlighting this very important topic.
Thank you Jim! I couldn’t agree more, our trees are absolutely holding us back.
It’s become very popular and trendy in the genealogy field lately to criticize large trees that often have obvious errors, but they don’t realize that having a large tree is absolutely essential for genetic genealogy. And building these large trees will unavoidably include errors (which the DNA will eventually help us correct!). If I only included individuals in my family tree that I was highly confident in based on my own research, it would go back just a small handful of generations.
Having an 81,000 name data mining tool thinly masquerading as an Ancestry.com family treeI, that a number of us contribute DNA results and research to, I appreciate what you and Jim Bartlett are saying. The most important thing is that one must be absolute ruthless is correcting errors when convincing evidence appears. Involving numerous cousins DNA is also very important. In Nov 2009, I got involved with DNA at 23andMe and a data mining I did go.
“Data mining” is a “computer geek” term for using a computer and various mathematical tools to find and verify information.
The AncestryDNA “White Paper” on DNA circles provided the foundation for the much simpler process that I use
http://dna.ancestry.com/insights/4879DC72-74D0-4DD0-916B-EBA8D02DC47A
Data mining deffinitations
http://www.anderson.ucla.edu/faculty/jason.frand/teacher/technologies/palace/datamining.htm
https://en.wikipedia.org/wiki/Data_mining
Another excellent post Blaine! On the one hand, it’s a little disappointing for me, by the 8th generation, I’m down to 10%. On the other hand, I have all sorts of opportunities to make new discoveries! Thanks again!
Thank you Jon! Hopefully DNA will help increase these numbers as well!
I did this exercise for a client last year and included the generational view. Then, I took two of the grandparents who had better known lineages. One of them had 100% known out past generation 6 using documents and other confirmed sources. This ought to be a regular part of a report. With continuing work, one can then watch their numbers.
John – it would be nice to be able to also include information about how confident we are in the identification of our ancestors. For example, past say 5 or 6 generations, my confidence gets rather low in many lines.
I first did the “by generation” in Feb 2014 when I saw that several bloggers had done their chart (using the net number — which is standard) and that one of these bloggers, in fact, had high percentages (which the tree that I am working on could not attain). So, I was motivated to split out columns for the two grandparents who were of New England stock (pun? – the other two grandparents were of recently arrived families) in order to see the incremental details. And, sure enough, those lines, being of Essex County, were quite dense.
Now, sources are of different strengths, as we know. If there were some rating for these (which I have seen proposed), we could then generate a number that is adjusted (weighted) according to source.
Too, how much is necessary to consider someone being known? For this exercise, that there was a name was assumed, as sufficient. There are several reasons for that choice (preliminary exercise, say).
If we used this ahnentafel that I have been sourcing, one can see five generations known back from 1805. So, add in two generations coming this way, and we’re up to seven.
http://thomasgardnersociety.org/html/Research/Ahnentafel%20LFW.pdf
As mentioned earlier, the number, in itself, has little meaning. But, one could get a feel for progress or not while doing work. Too, firming up sources would raise the number, if done right. And, there is the pedagogical value which is what this discussion seems to be about. For one thing, it brings to fore the number of people involved in one’s past. Then, the whole notion of what is enough sits there awaiting our attention.
When I first ran across this type of chart, it seemed to be taken as a little exercise for show and tell. However, it could very well be used to manage work. For me, the ahnentafel coupled with sources does the same thing. Actually, I had forgotten about the numbers until your article. But, now, I’m interested, again.
Given the interest, I intend to regenerate the chart using an ahnentafel that is fully referenced. From this, we will be able to see the sources. Then, we can talk weighting, etc.
My Feb 2014 chart.
http://2.bp.blogspot.com/-ZvVizp5QU5E/UwUJQE1IE0I/AAAAAAAABf8/svp3PkY6IVE/s1600/Ancestor+score+summary.jpg
It might even be more useful to breakdown the chart even further – one for your paternal and one for your maternal line. I know my charts would certainly be more complete on my paternal side where I have done a lot more work.
I agree, it would be interesting to see; my own maternal and paternal sides would be very, very different. But we want to be able to share information about our entire tree with our matches, since a shared segment of DNA can come from any line in the family.
I was thinking the same thing. There is a huge difference in the sizes of my maternal and paternal trees. It would be an interesting exercise to compare the two, if for nothing more than motivation to fill in the gaps.
Quora question.
https://www.quora.com/Is-there-anyone-for-whom-all-1-024-of-his-her-10th-generation-ancestors-are-traceable-all-of-them-separate-individuals/answer/John-M-Switlik
After plodding away for the past two years on Triangulation, I now have 90% of my DNA in specific TGs on both Maternal and Paternal sides. So as new Matches come in, I can very quickly determine which TG they are in, and thus which side. So now, when I contact new Matches, I only send the Patriarch list from the proper side. Basically it divides the problem in half….
That’s excellent Jim, and I’m VERY slowly working toward that goal myself!
What difference in the % does having double cousins make? My father was a double cousin, since my grandfather married my grandmother & 2 siblings of each of them married each others’ siblings, So the same great grandparents appear on 3 branches. (It was a close knit ethnic group that came to the USA in the late 19th centruy.)
Kay – this won’t change the chart or % at all. If you were to chart only your ancestors, you’ll see that this marriage of 3 siblings to 3 siblings doesn’t affect any of your ancestors.
I does make filling in ancestors easier, though.
Jim, you are my hero, and all your research has helped answer some of my thornier problems – thanks.
Blaine, thanks for yet another thought provoking post. My own experience has recently been exasperated by trying to use Ancestry DNA matches. I have two promising matches for breaking down two ‘brick-wall’ grandmother lines. Possible common ancestors with uncommon names living in the same county. After begging and pleading, I finally got their data uploaded to GedMatch and found, in both cases, after extending their trees, and comparing some known common ancestors, we are related on different ancestral lines than the ones I am looking for. So it goes.
But I have learned. I don’t pay any attention the Ancestry DNA “matches” unless that are already on GedMatch or FTDNA.
Marci – so glad you found this post helpful! It is always challenging getting AncestryDNA matches to upload to GEDmatch for comparison, but keep it up and hopefully you’ll get the breakthrough you are looking for!
Blaine, I am right with you on this one–and have been thinking about your post ever since reading it on the 11th. I’m finding, given your example of the three researchers with varying levels of research experience, that going the extra mile for those other researchers can help. Since so many of my matches don’t have their own trees fleshed out to the generational level that meets Jim’s “sweet spot” of 6th to 8th cousin (in other words, a chart completed out to the level of 7th great grandparent, at most), I’ve begun tracing the descendants of each of the collateral lines in my tree–siblings of each generation on downward. While that makes for large trees on my part (I’ve also separated out into two trees, one for paternal, one for maternal lines), it does help others find matches in my research that they can work with.
I’ve built out my own chart and have it set up to update when I add new generations of grandparents. Now I’m trying to figure out how I can develop a formula that computes the number of potential cousins in each generationbased on the number of known children of each set of grandparents….
I have several of these issues. My father is unknown but all the below matches which match myself and my full brother but not match my maternal half brother, go back to one couple and are verified by my own research and very well documented. This couple emigrated from Ireland circa 1860 and remained in Chicago area until death.
Problem 1. NS, JB not on Gedmatch so I can’t verify segments or overlap.
Problem 2. NS not interested obviously since there are no replies to my inquiries and there is no tree.
Problem 3. Little to no IBD overlap between NK, EB, TS, JM, DM
Problem 4. Although I have extensively research any of possible tie between NK and EB or TS and find nothing the possibility remains.
Name,Match Name,Actual Rel
NK,JB,2nd,226.385
NS,SN,?,139.05
NS,NK,?,134.64
NK,SN,2nd 1r,87.819,
SN,JB,2nd 1r,82.63
NS,DM,?,75.63
NK,DM,?,75.5
TS,JM,?,70.7
TS,NK,3rd,49.27
EB,SN,3rd 1r,43.8
EB,NS,?,42.15
JB,NK,?,38
TS,DM,?,37.9
EB,DM,?,35.3
JB,DM,?,30.4
EB,NK,3rd,17.2
JM,EB,?,11.3
EB,JB,3rd,7.343
So even though all seem to have the same couple as GG or GGG Granparents I can’t rule out that the matches seen are from differing lines of descent. So until something else comes in I am kinda at a loss.
Dan
last number in the table is the total cM
I don’t understand your generation number 4 line. Under “BY GENERATION” you have not identified 2 people but under “OVERALL” you have not identified 3 people. Is that a misprint or do I not understand?
Thanks!
If 14 are known at Gen 4, then the accum value of overall would be 28.
If 27 is right, then the known would be 13.
Only been triangulating and mapping DNA for about 15 months but have been doing genealogy for 16 years. My mom has some very large matches that are going way back on one chromosome. I have not only triangulated the match between 5 descendants of the same ancestors (2 siblings) but have found at this point 10 descendants of one couple who are sharing 24-56 cM with all 5, my mom having the longest. The couple happens to have been a neighbor of the one direct ancestor we don’t have a wife for and old enough to be her father. What I started doing on large matches (I mean greater than 40 cM) is putting them in my tree and doing the genealogy back myself. Sounds labor intensive but given the “copying” hints in ancestry on tree’s, well, I look for census and proof. Mom’s largest match here is 74 cm an adoptee and the next is 65 cM. She is one of the many descendants from this couple who can’t be closer than my mother’s 6th grandfather, and is 5-6th for most of the matches. I just can’t explain it. It’s not an early colonial family either, though it is a longhunter one who may have endogamy that I don’t know about a generation or two back.
I find the GG coupled with traditional methods is a catalyst for validating research and new discovery. The DNA segments may not give you names and occupations, but they sure do get you in touch with folks who are researching in the same area and may have sources (and more more relatives) to work with.
My father has a match with a common ancestor who happened to be his 3rd gr-grandfather. We were stuck pushing further back. The match had some primary research that got him to certain point, but ultimately blocked. If it weren’t for the matching segment, he wouldn’t have gone through his brick wall, and we corrected a sublte, yet important error using the match’s primary research that unblocked us in a different branch. I also discovered my 2nd gr-grandfather had a second wife.
The GG is a wonderful collaborative tool. It joins folks together to solve mutual problems in a constructive manner. The combination of GG and traditional methods accelerated problem resolution. I would say the cost in testing has paid for itself already in the time required to figure some of these problems out the old fashioned way.
I cant remember when I didn’t know that you for number of people in a generation, you just doubled the number from the previous generation, so there are 2 × 2 × 2 × 2 × 2 = 2^5 = 32 ancestors in your fifth generation back. It is only more recently that I learned it was almost as easy to figure out total number of ancestors back to a particular generation. The total number of ancestors is just double the number in the last generation, minus 2. So I have 62 [ 62 = 2^6 – 2 = 2( 2^5) – 2 ] total ancestors for all the generations back to and including the 5th.
This is such a profound topic, I picked it for my first [genetic] genealogy blog 🙂 http://bgengen.blogspot.cz/2016/10/we-begin.html