The genealogical community has a serious issue we need to talk about.
We are amassing one of the largest collections of genealogical information ever created, in the form of DNA match data. As of October 2018, approximately 20 million people have taken autosomal DNA (atDNA) tests, and that number continues to grow rapidly. DNA evidence is being added as an additional record to support existing genealogical conclusion, being used to generate new hypotheses, and helping break down decades-old brick walls.
However, since many genetic matches are either unwilling or unable to respond to communication or provide permission for public use of the genetic data, much of the massive database is potentially locked behind privacy walls such that the information can’t be utilized in scholarship and can’t be publicly shared. Indeed, Standard #8 of the Genetic Genealogy Standards (PDF) mandates the following:

As a result, we can’t name a living match in our writings (such as blog posts, social media posts, or articles) or presentations without written or oral permission from the match. This is potentially a devastating loss.
Is there anything a genealogist can do, or use from the genetic match information, if the match is non-responsive or refuses to grant permission for public use of the match information? Let’s look at some possibilities.
(This blog post is intentionally focused on AncestryDNA matches since there is no segment data (only a total shared cM amount), making it potentially the most difficult to use in these types of genealogical conclusions.)
Using Semi-Anonymous Genetic Match Information
First, there is at least one maxim that should NOT be part of this conversation: we cannot provide the name or username of a LIVING genetic match in a public writing or presentation without the permission, written or oral, of the living genetic match. Period, non-negotiable.
Beyond that maxim, what can we do to utilize matching data such as that provided by AncestryDNA, where the match doesn’t respond or provide permission?
In the following figure I’ve provided a real-life example. The subject (Allen Mullin) of this study is a great-great-grandchild of Hamilton and Susanna (Steen) Colwell, and he shares DNA with three of his third cousins (Match #1, Match #2, and Match #3). The amount of DNA each shares with Allen Mullin is provided in the figure. However, the name of each match and the name of the parent is anonymized for privacy.

Should we anonymize just the parent (as in this example)? Or should we privatize the parent? Or more?
To play devil’s advocate, doesn’t anonymizing the parent still technically reveal the identity of the three matches, in contravention of the Genetic Genealogy Standards? After all, we can form a reasonable hypothesis about who they are.
Maybe not. A small technicality is that I’m not identifying the matches; instead, the reader must go out and intentionally identify or try to identify the name of the test taker.
However, the biggest mitigating factor is that the universe of possible matches is large, and this doesn’t identify which people in that universe of possible matches has undergone DNA testing. Indeed, the argument that we can hypothesize who they are may even weigh against the argument that we cannot use this information. In this example, Elizabeth Colwell 10 grandchildren, Hamilton Henry Colwell has 12 grandchildren, and Jane Viola Colwell has 17 grandchildren. Thus, there are many people that Match #1, Match #2, and Match #3 could be, at least in this example. In other examples, there may be fewer possible people in the universe (potentially even just a single person).
Here’s another version, showing the initials for the parent:
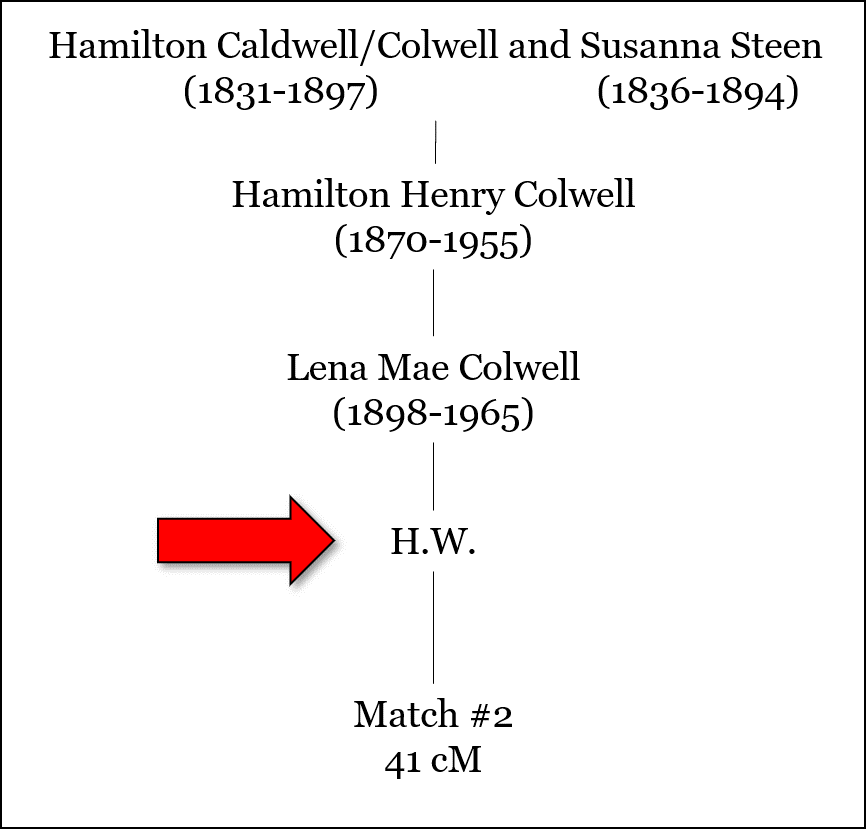
Is that private enough?
We Already Knew the Universe of Possible Matches
Indeed, to build on that last point, I already knew the universe of possible matches, and so did you, even before DNA testing! We can use traditional genealogical research to identify all the descendants of Hamilton and Susanna (Steen) Caldwell/Colwell using publicly available information. All we’ve added to this figure is the amount of DNA shared by several people we’ve already identify in the tree.
It may be different for cases where a family or relationship was not known prior to a conclusion that pieced the family or relationship back together. However, once an ancestral couple is identified, a genealogist can typically identify the descendants of that ancestral couple using traditional genealogical research.
Obviously, genealogical conclusions that involve a misattributed parentage event or other potentially emotional result will likely need to be handled differently, potentially with greater privacy. Additionally, the issue of using genetic data from matches that are responsive but refuse to provide permission is another important consideration.
Replicability?
One of the problems faced by a genealogist using matching information such as that provided in the figure above, is that there is no replicability. Every genealogical conclusion should be replicable, meaning that the same conclusion should be reached if the research is repeated by another genealogist.
This is one of the important reasons why we cite our sources (in addition to, for example, providing information about a source such that we can evaluate its ability to serve as a source, the strength/quality of the source, and so on).
However, as a scientist, I know there are issues with the replicability of the genetic match information, since I do not – and should not – have access to the test taker’s account. For example, providing the name of the match (with permission) does not give me any greater ability to replicate the data, since I can’t access a test taker’s account as a third party. Suggesting that a researcher independently re-test a test taker as a method of replicability is not realistic.
Transferring raw data of two matches to GEDmatch to enable sharing of GEDmatch profile information (“kit numbers”) to researchers to perform independent comparisons is a good way to deal with replicability, but even then it does not guarantee that there is or will be replicability. Was the proper data transferred to GEDmatch? Will GEDmatch be available in the future? Can’t GEDmatch be gamed with data? Additionally, although I very much laud the inclusion of GEDmatch profile information in a genealogical writing to enable readers to replicate the research, this puts in place an even higher barrier and reduces the amount of usable genetic data by several orders of magnitude. True replicability likely requires access to the raw data of the two test takers, or even saliva samples from the two test takers, neither of which are possible.
Providing Supporting Documentation
One way to address the replicability issue is to provide information that essentially recreates the match information seen by the two matching individuals. This information could be provided in the genealogical writing or presentation, or included as supplementary information.
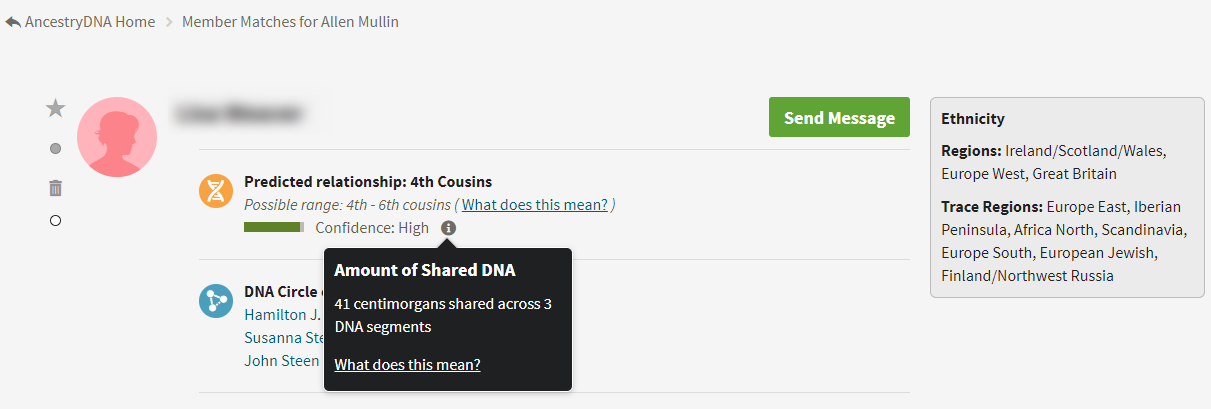
In the images below, for example, I’ve provided screenshots of the three genetic matches (Match #1, Match #2, and Match #3) from the image above with the names blurred for privacy, seen with respect to the subject of the research question (Allen Mullin):
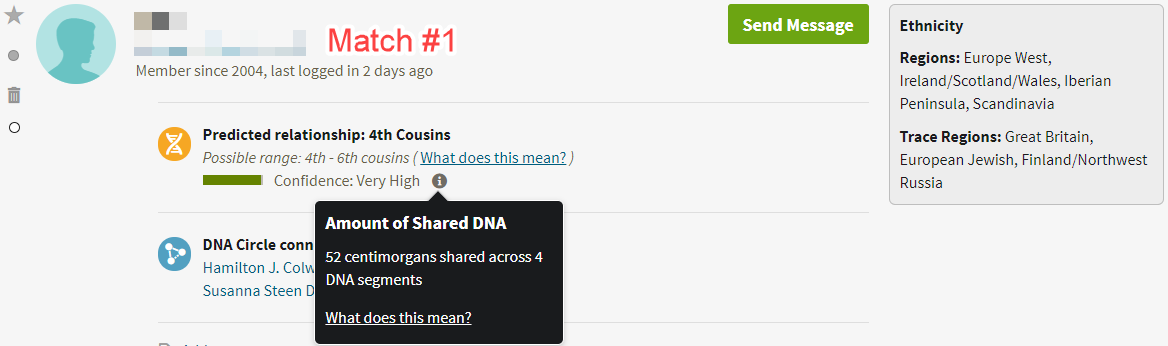
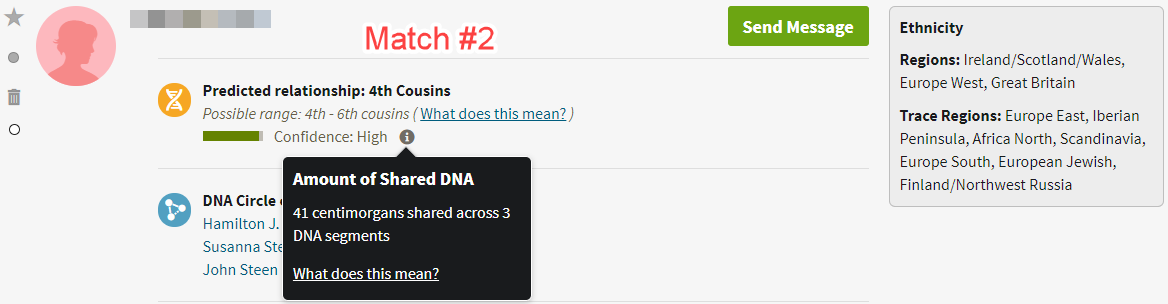
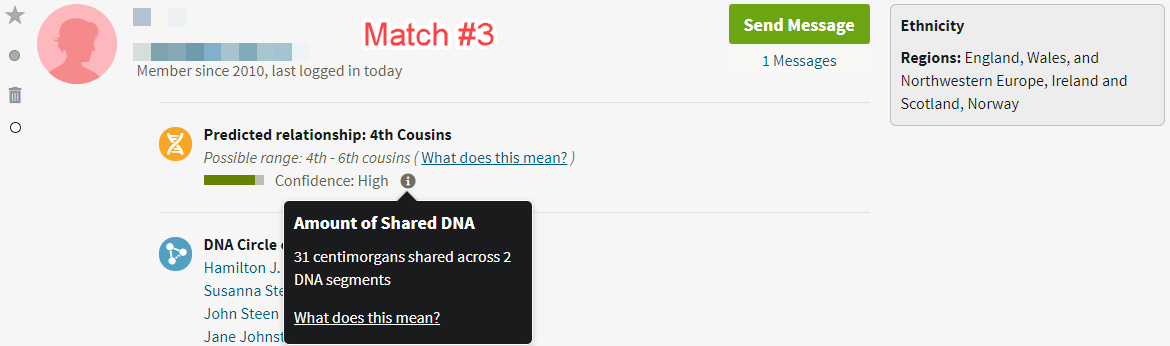
As suggested by someone in the GGT&T Facebook group, the screenshots are probably better if they include the name of the test taker, shown by the “Member Matches for Allen Mullin” in this image:
The conclusion that we cannot use the genetic data of non-responsive matches is potentially too far-reaching. There may be ways we can utilize this DNA evidence in public writings and presentations to support our genealogical conclusions.
What are your thoughts?
I think another related point to look at is for semi-private (i.e. at a conference, not blog post or YouTube video) presentations, do you have to anonymize all tester information? For static slides, this is easy. But if you are trying to do a live demonstration to show how to use match data, anonymizing all identifying information is impossible. Does this preclude live presentations of any of the testing companies websites or GEDmatch?
And consider one to one consultations.
Great question. I sometimes do live demonstrations. I ask that people enter into an informal agreement with me that the live demonstration raises privacy issues and that they will not take notes or otherwise violate privacy as a result of the demonstration. One benefit is that it is very transient. This isn’t perfect, but it is the only option other than static slides.
I would not feel comfortable doing this in a recorded presentation, or via a webinar where people can take screenshots.
So is it simply the personal information that needs to blurred? Is it alright to use the actual cMs information, i.e. how much they shared with the tester, head of the project.?
Thanks
There’s no question that a living person’s information needs to be blurred unless they’ve given permission otherwise. I don’t see any issue using the shared cM amounts.
Oh forgot I have another question. So example, for random matches at Ancestry all of the information that should be redacted is, what do you do about the source? The name of the tree is part of the citation format from EE. Haven’t figured out how to keep the citation but without the tree name.
That’s a great question. The match citation typically won’t include the name of the tree. I suppose citing their tree might, so I think we’d have to come up with other alternatives
You’ve raised some great questions! I like how you are privatizing the names of the DNA matches and their parents and how you are sharing screen shots, but privatizing the names. I know it takes a lot of work! But, it is important.
Thank you! This is a very important topic and discussion.
Ancestry does not remove tests of people who died at some point after submitting the test. In many cases, their living relatives probably don’t know the test exists, there is no living survivor contact information connected to the tests, and therefore, no response or permission will ever be received.
Very true! So this issue will only get worse over time.
In the case of a peer reviewed journal article, perhaps the editorial process could include a qualified panel to review the paper trail documentation that supports the atDNA matches and certifies that the anonymous test takers’ lineages are correct. Then the evidence could be presented anonymously for public consumption and benefit, but privacy can be maintained. It seems that anyone who has submitted their atDNA to a public forum like Ancestry should expect some exposure and has already given up a degree of privacy. Of course, if they have designated their test and tree as private, their privacy should be respected unless they have given special dispensation for the paper or presentation.
Yes, the DNA articles in the NGSQ have done this (that is, editors have reviewed the private data).
However, the vast majority of genealogical conclusions are not published in journals or in presentations, so we need mechanisms in place to utilize AncestryDNA data in these write-ups.
If a DNA match has not given permission to share their name, this approach makes sense in terms of a reasonable approach. Maintaining the privacy of the living (as most programs like Ancestry’s public trees do) is easy enough. What about the privacy of those who have passed away? If the parent(s) of a match are no longer living, do we need to protect their privacy even though there are numerous public records available for them (SSDI, Death Certificates, Obituaries, and Cemetery Listings like Find-a-Grave). Are we safe in publishing the names of the deceased individuals (including matches or parents of matches)?
In many jurisdictions, the dead have no privacy rights. So I have no issue publishing information about the deceased.
The problem, however, is when publishing information about a deceased individual inadvertently identifies a living match. That’s why my tree in the figures includes “PRIVATE” for the parent even though the parents are all deceased.
Hi Blaine. Thank you for another timely topic. Maybe the 2015 Genetic Genealogy Standards are not quite up to date reflecting current conditions in the privacy and usage atmosphere in late 2018. A lot has happened since late 2014. Also, when demonstrating the tools live using living AncestryDNA matches, I think the relevancy of the Ancestry.com privacy and usage policy would need to be taken into consideration.
Maybe we are talking about more than one topic here: 1) public demonstrations using AncestryDNA provided tools in a live rather than screen shot format, 2) Presenting findings of DNA analyzed using a combination of various sources and tools, and 3) the Genetic Genealogy Standards’ timeliness with regards to the privacy and usage policies for each DNA company and DNA policies in general as they change. A bit of a tricky balancing act!
I reviewed the Ancestry privacy and ToS policies and didn’t see anything that was directly on point. I’d be interested to see what others find or think about those policies.
Reviewing the 2015 Genetic Genealogy Standards, I don’t see anything I would change with regard to privacy, but I’m always interested to hear what others think.
Great article!
I like the screenshot of Ancestry test results. But shouldn’t we also blur out the gender of the match? By revealing the gender you may have cut the pool of possible grandchildren substantially.
Great question! Should we? I’d be interested to hear what you and others think about it.
Hiding the gender would make it impossible to properly document matches on the X chromosome.
This is an issue that I’ve been struggling with over the past couple of months. I managed to identify two likely candidates for my grandmother’s biological father (with one being more likely than the other), and I think it’s a decent example of how to determine parentage. In other words, I’m pleased with my work and want to submit it to be published.
Except that I’m no longer on speaking terms with the cousin who enabled me to figure out the connection. Without this cousin telling me who their grandparents and great-grandparents were, I’d never have solved this case. Without them getting one of their cousins to test, I’d never have solved this case. This cousin wouldn’t tell me who the other cousin was (by the other cousin’s request), but I figured out who the other cousin was based on initials, and family trees and obituaries posted on Ancestry; did I violate the other cousin’s privacy by doing so?
Am I ethically bound to never publish my findings? Am I ethically unable to discuss the findings with other descendants of my grandmother, due to the cousins’ privacy concerns (once I tell family members, I have little control over who they choose to tell)? Is there an ethical conflict between the cousins’ desire for privacy, and our family’s right to know who our (genetic) ancestors were?
You could always publish using pseudonyms (and say you are using them due to privacy concerns). Editors could review the actual evidence but publish using fake names.
As far as the cousins’ right to privacy vs your family’s right to know their genetic heritage, that is a tougher question, in my opinion.
What promises about privacy did you make at the time they gave you information.DNA test?
Is it possible to reveal the name of your great-grandfather to family and not reveal the identity of these cousins?
Is your family in communication with the cousins’ families? It’s tougher to reveal information and still respect their concerns if you’re all in a small town together.
Do you know why specifically they do not want this information public? Is it concern that new family members will “want something” from them? Embarrassment over a paternity event 100 years ago? That might make a difference in the best way to handle it.
These are very good points. I think it is reasonable to provide an initial for the given name and then the surname if it can be derived without having any direct knowledge about who the living descendant match is. This does not provide enough information to violate reasonable personal privacy concerns. Am I wrong? I publish information in this format regularly. An example can be seen at http://gigatrees.com/users/home/saga/dna/DNA-I4 .
Looking to the future, has anyone given serious consideration to forming a public database where people could voluntarily upload all of their own DNA raw data which they have (autosomal, Y, mt), along with their identity, placing that information permanently within the public domain for the benefit of any researchers who wish to use the data? Such a database would satisfy the serious researcher’s desire for reproducibility, although there are some problems with such an approach.
The most obvious problem is that many people who have uploaded data to places like Gedmatch might have reservations about making their data completely public. Still, if a significant number were willing to do this, it would allow significant progress, and many who were unwilling to share such data during their own lifetime might be willing to include the public uploading of such data in their last will and testament. There are also legal questions, such as what to do with the raw data of deceased individuals who did not give explicit permission for public sharing during their lifetime.
Has such an idea ever been discussed in detail?
Stewart, Gigatrees stores anonymous relationship data for atDNA matches in its database and publishes the results in several tables at:
http://gigatrees.appspot.com/stat-dna.html
The hope is that the samples sizes for each relationship type grow large enough such that the calculated results will be repeatable and then useful to predictability algorithms.