Given the lack of a chromosome browser, the Shared Matches tool at AncestryDNA is one of the most powerful tools available to genealogists. Once you have a list of genetic cousins at AncestryDNA, you can mine the Shared Matches with each of those cousins, looking for patterns of shared ancestry among the shared matches.
This works better if you have a well-researched tree and several tested relatives on multiple different sides/branches of the family.
PLEASE. I know I say this a thousand times in the post and the caveats at the end, but please use caution with this. I’m posting this because I found it useful, and I would like to get feedback on what others are doing in this area, particularly with regard to automation of this process. This is dangerous, so use caution!
The Shared Matches Tool
The Shared Matches Tool can be found by clicking on a genetic matches’ profile, and then clicking on the SHARED MATCHES tab. It’s not uncommon to have many shared matches, no shared matches, or any number of matches in between 0 and many.
If you’ve tested close relatives, you might see them in your Shared Matches list. For example, I’ve tested both my parents, and I get three (3) pages of shared matches with each of my parents.
Now, you might say that together my mother and father should share ALL of my matches in common, but that would be incorrect for several reasons. First, it is common that 20-30% of matches are not shared by either parent (which is either a false positive for you or a false negative for your parents). Second, the Shared Matches tool only shows your fourth cousins or closer shared with a match. There are MANY limitations to the tool, be sure to understand those limitations completely (see “AncestryDNA Announces New IN COMMON WITH Tool“).
Clustering Shared Matches into Groups
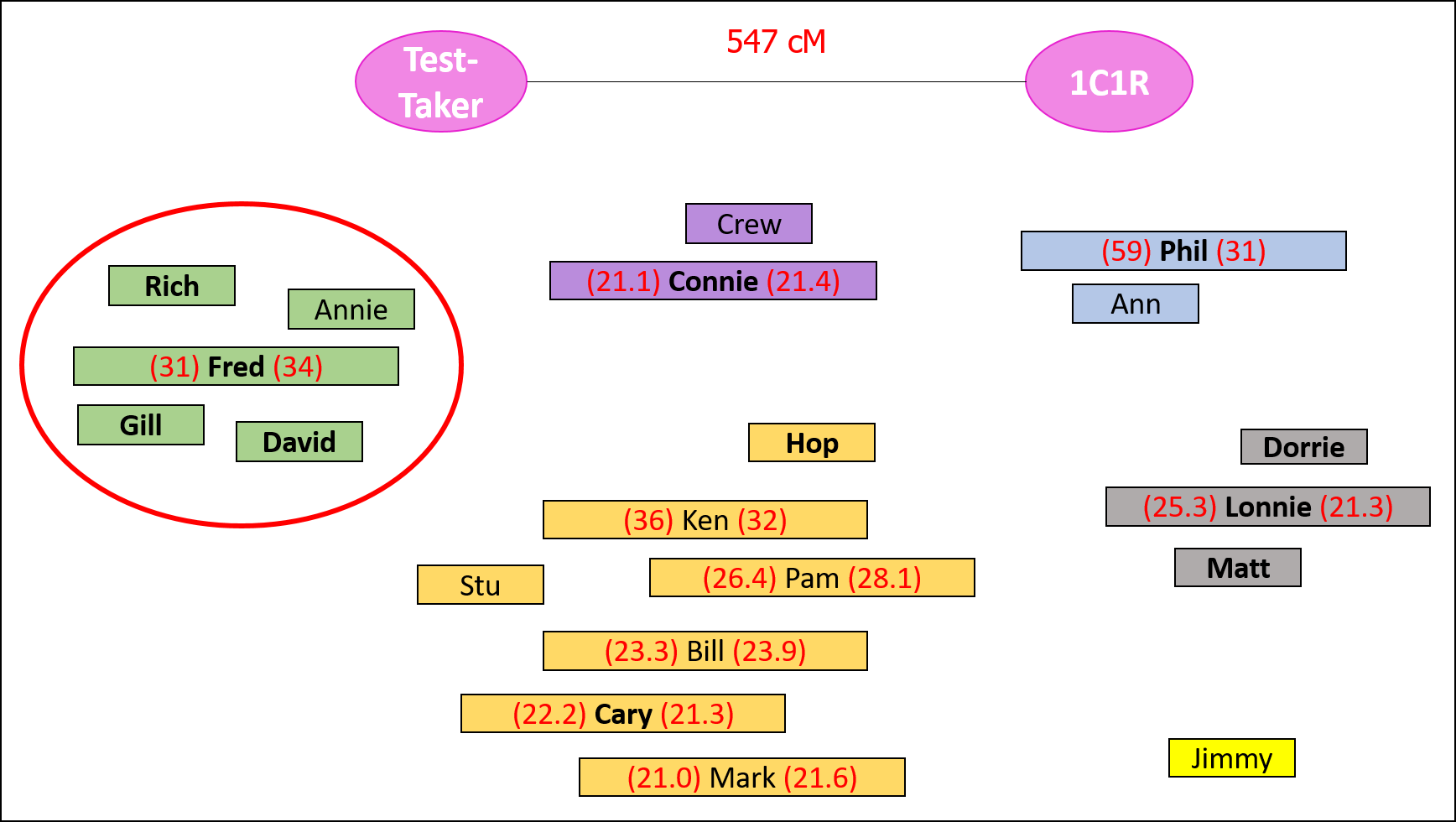
For this exercise, we’ll look at the shared matches between a Test-Taker and her 1C1R, who share 547 cM in common:

I focus on these individuals, for example, because I’m particularly interested in their shared ancestry, some of which I know and some of which I don’t know:
![]()
I log into the Test-Taker’s DNA results, and then I click on the profile for her 1C1R. There, I click on Shared Matches, and I get a list of just nine matches (that is, just nine of Test-Taker’s fourth cousins or closer are also shared with the 1C1R). Notably, this list is on the small side.
These are the shared matches between the Test-Taker and her 1C1R (all names changed, of course). The shared matches with public trees are in bold:

So, Phil is a match shared by both the Test-Taker and the 1C1R. This suggests that Test-Taker, Phil, and 1C1R share a common ancestor. BUT! It is entirely possible that Test-Taker and Phil share an ancestor while 1C1R and Phil share an entirely different ancestor.
Each of the Shared Matches may, in turn, share matches with the Test-Taker and/or the 1C1R. For example, in the following graphic, Ann is shared in common with Phil and the Test-Taker. Pam and Stu are shared matches with Ken and the Test-Taker. And so on:
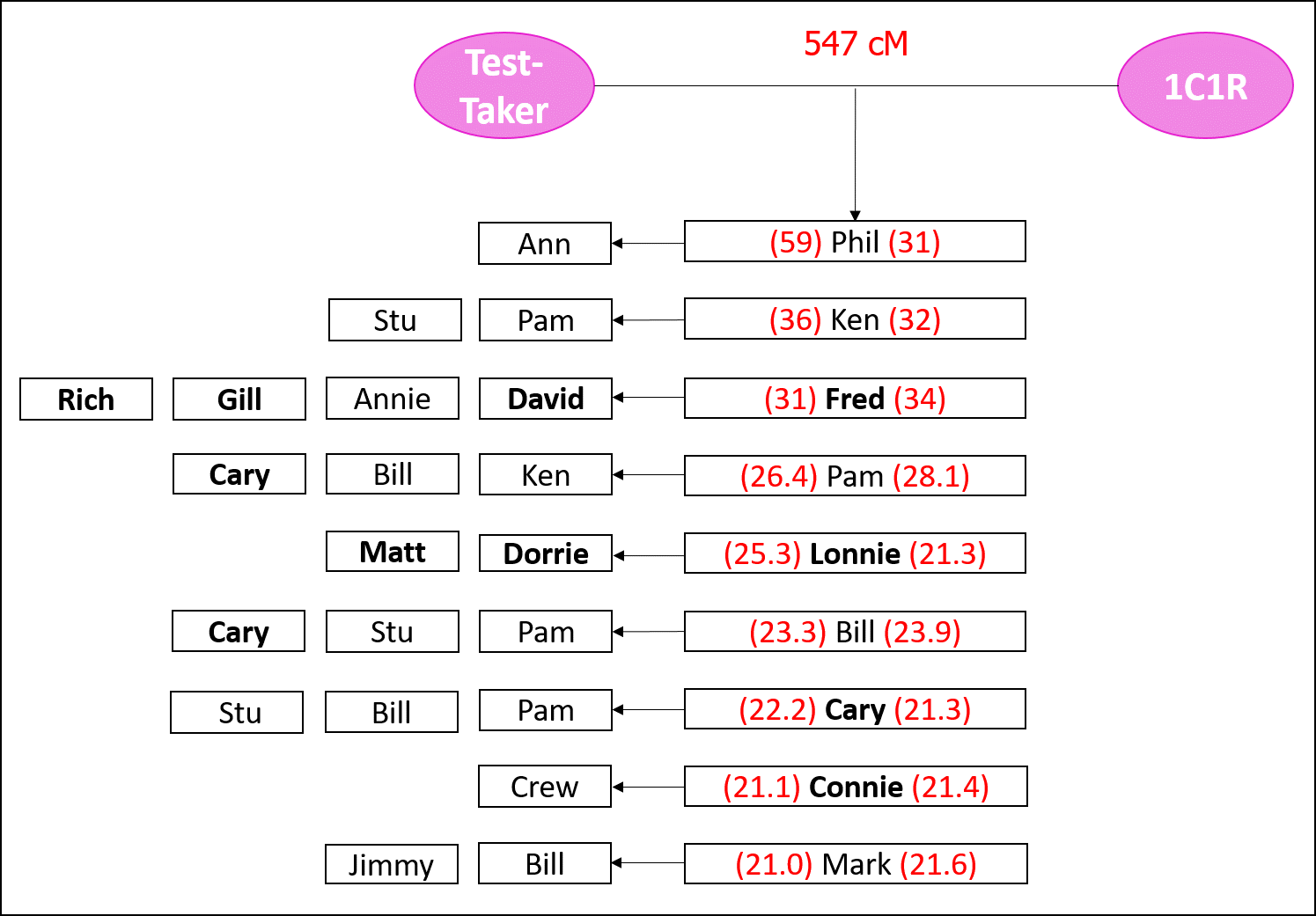
Repeating this on the right side are the matches shared in common with a Shared Match and the 1C1R. For example, Phil and the 1C1R also share Ann in common:
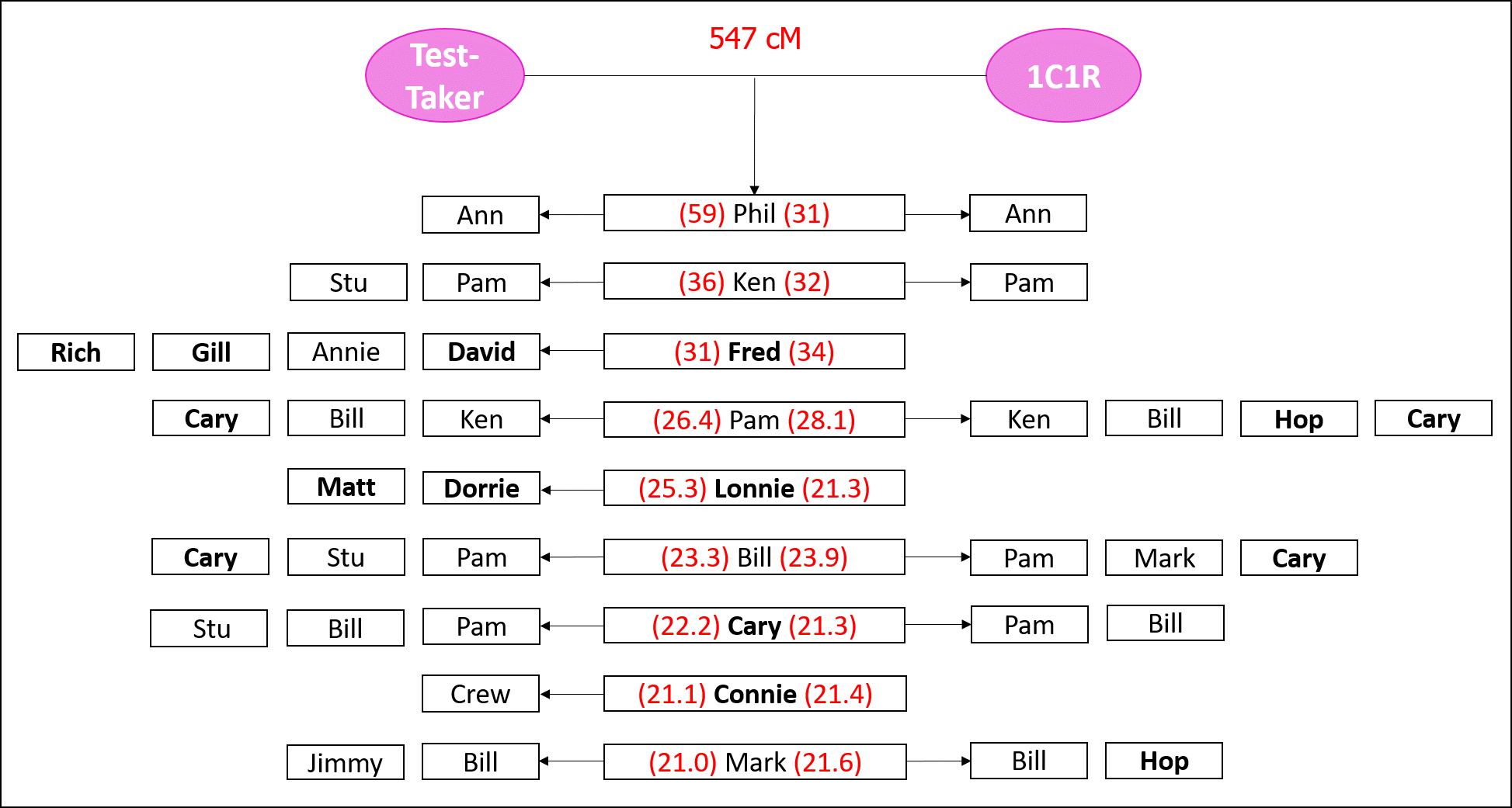
Now, I can take these shared matches and cluster them into groups, while understanding that this is very, very risky.
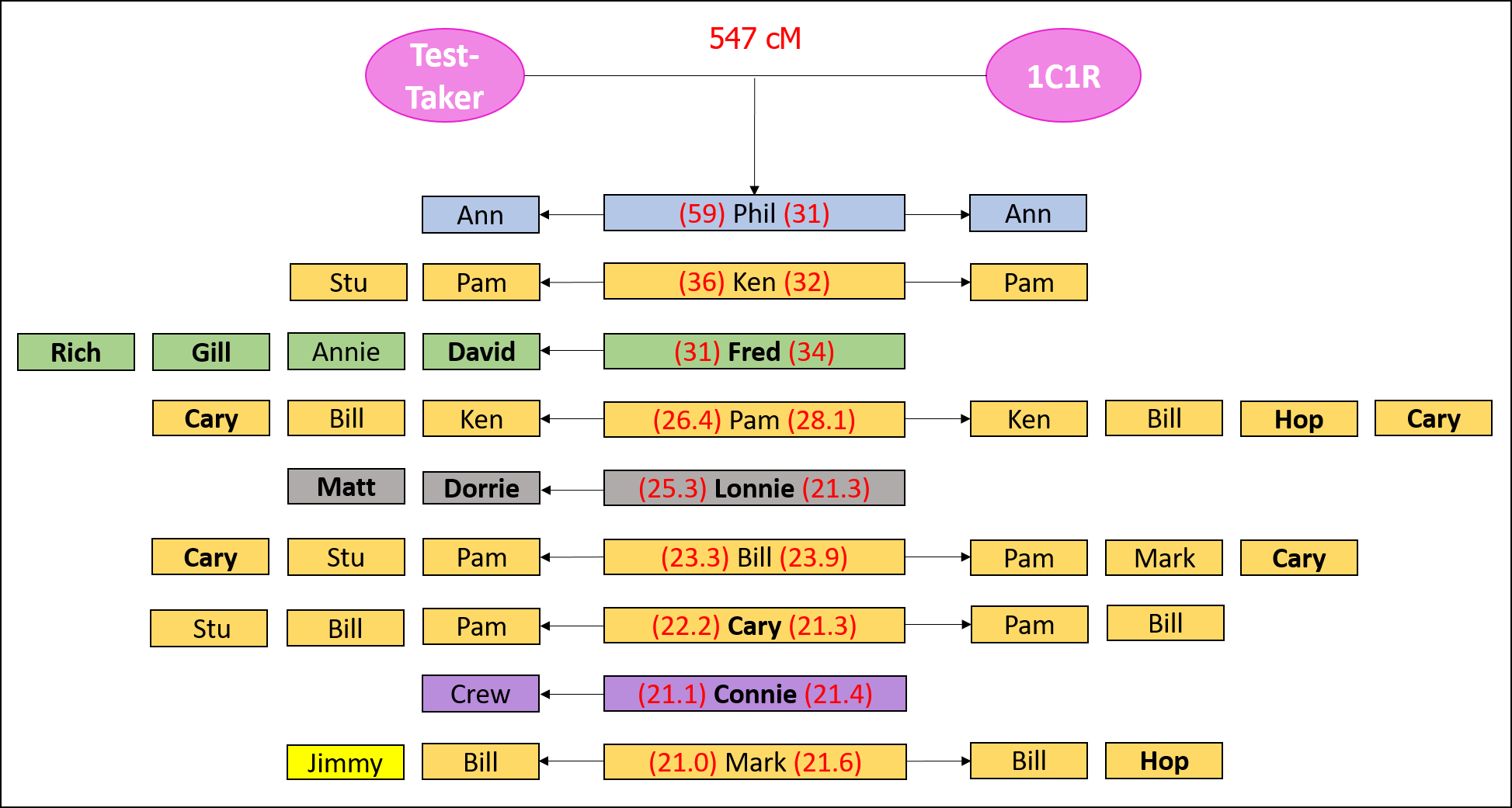
I am risking, for example, bringing in shared matches that are actually shared on different lines. As example, “Jimmy” in the graphic above shares matches with the Test-Taker on the opposite side of the family (i.e., the 1C1R is on the paternal side of the family, and Jimmy looks to be related on the maternal side of the family). So, proceed cautiously.
I can format the shared matches clusters a little differently, eliminating repetition of names:

Now, I can mine the clusters for shared ancestry, understanding that I must proceed carefully. For example, the simplest way to proceed is to see whether any of the clusters have a known relative in them. If so, then I can proceed with the hypothesis that those individuals are related to Test-Taker and/or 1C1R through the known relative.
Another way to mine the clusters is to look through their trees to find shared ancestry, working with the hypothesis that their shared ancestry is how they might be related to Test-Taker and/or 1C1R. For example, since Dorrie, Lonnie, and Matt all have public trees, I can look through their trees to find ancestry that they share in common. It may be that it is only a location that they share in common.
Using this method, I discovered that Fred, Rich, Annie, Gill, and David are descendants of a single family (on multiple different lines) from Upstate New York in the late 1700’s and early 1800’s that are helping me solve my great-grandmother’s adoption (which is on the line of the Test-Taker and the 1C1R):
CAVEATS
Please keep the following caveats/tips in mind:
- Of course, transfer to GEDmatch and convince your matches to transfer to GEDmatch. But almost all of them won’t, so this is a tool for working around a lack of segment data.
- You MUST understand the limitations of the Shared Matches tool at AncestryDNA. It does not show you all of your shared matches. See “AncestryDNA Announces New IN COMMON WITH Tool.”
- As always, this may be problematic if there is significant endogamy. However, if there is only endogamy on one side or in one branch, you may be able to use that to your advantage (as that branch or side may have plenty of shared matches, making it clear that it is indeed that branch or side).
- These are just CLUES. Everything discussed in this post can only serve as a clue, and requires more research to flesh out the clue and perhaps lead to a conclusion or simply a piece of evidence.
How have you used this clustering method successfully as a clue? What ideas do you have for furthering this method or automating it?
I never really took advantage of this tool until a couple of weeks ago. I had a “new” match, predicted 2nd-3rd cousin on ancestry. I used this tool and found out that she had only four shared matches: 1) with me, 2) with my nephew and 3) someone I’d never heard of. As it ended up, the 3rd person had a tree and I was quite familiar with one of her lines. I contacted the “new” match and found out she was adopted. With a couple of weeks of researching every line, I identified her probable biological father. Gedmatch confirmed that the amount of shared cMs was exactly within the predicted range, as well as matches to my aunt and uncle who were on Gedmatch. Now our dilemma is whether or not she should contact her three half-siblings and ask them to test. As these are all second cousins to me, I know they have no knowledge of this possible relationship. This is the first time I’ve been confronted with this.
Are you in the Facebook group DNA Detectives? That would be a great place to post this question.
Contact all 3 of your 2nd cousin’s ask them if they’d be willing to take a DNA test, leave out the specific reason (1/2 sibling) & if one or all of them agree. That’ll back up everything. Then you guys will just have to figure out if was their mom or their dad.
I have found 2 cousin’s (in different lines) that were adopted out. The first was easy to figure out, though the 1/2 sibling of the new cousin, isn’t talking to either of us (no loss for me as I never knew them till this test) the 2nd cousin, i have an idea of who might be the dad, but I don’t know any of the descendants from him, so I can’t make contact. So me & the new cousin just have to hope one of them takes the test soon LOL
We discovered who my husband’s “real” dad was ….. after 50 yrs of him being abandoned at birth & disowned by the rest of the family….or who he was told was his family (freaky thing is, he looks like that family).
My sister tested with Ancestry (gift from her daughter) and I did not so this past few months is the first I have used Ancestry much. I get lost trying to organize the data and find my self constantly repeating things. I now have test some of the grandchildren so I search for a surname and look for the little cluster and look at those folks, first, make a note there so I don’t have to look at all the names again, even if I am not sure about this surname. Other often pop out so I note them also and then hit favorites. I am starting to get a lot of stars. I just tried your technique on a random match and then what I noticed was several already had stars and one was an Immel and one a Shunk and that is my father’s ancestral grandparents as a couple. I then tried to navigate back to the “shared match” to see if the other 6-8 that showed up matched and I lost navigation. I think it could be helpful but how to go back and forth in their pages. It drives me nuts and I was a software tester.
THANK YOU, Blaine. Yes I am shouting for joy, as I am dealing with this right now and just have not been able to get my head around how to represent all the relationships. I will be using this. You are brilliant and generous.
Thank you Blaine! There’s an incredible amount of endogamy on both my paternal and maternal families. This truly makes it extremely difficult, although not impossible, to isolate potential matches or family branches. Most of my cousins matches show to be closer than they actually are, that’s due to the amount of shared DNA among family after family of marrying relatives.
I find the shared matches really useful and thank you so much for this. I did have an adoptee match, and using this feature and the one on Gedmatch, I fiddled with it for some time and informed him that I was virtually certain that one of his birth parents was a _____ from Iowa. Late in November, he did find out his birth mother’s name and talked to her (long story) but my prediction of the other name was correct. Which blew my mind. It took a lot of time, but I was stunned that, looking hard at and researching the people who matched him and several of my known relatives, I got the name right.
I so appreciate what you are doing for our community.
Kathleen, This was precisely my experience. The shared matches were the first clue. Then I asked her to transfer her results to Gedmatch which narrowed down the possibilities significantly. For instance, she matched my uncle, but the data on gedmatch proved that they did not share enough cMs for him to be the father. It probably took me a week of extending every family line in my tree until I found someone who had the other criteria. My prime suspect lived on the same street as the biological mother in the correct year and was also “in the navy.” The fact that he was in the navy was the only clue the bio Mom provided. Using the ISOGG chart, I was able to see that the shared cMs with me, my aunt, uncle and nephew all aligned perfectly. Now the challenge is whether or not she should contact her three potential half-siblings. It does make me nervous.
Maybe better for a 3rd party (maybe you) to contact the 3 potential half-siblings and give the adoptee’s contact info.
I have similar situation, but the “woodpile event” occurred about 120 years ago and is even harder to prove the exact culprit…..but the time lapse lessens potential embarrassment.
Wasn’t getting it right the most wonderful feeling? I hope I can continue to sort things out and hope it will not be as time intensive as it was!
Blaine: My apologies for being a bit dense. I am relatively new to AncestryDNA game and still trying to understand how this all works. I understand how you created the center match list between the test-taker and 1C1R with having the log-in information for the Test-Taker. From that match list, one can go back into the Test-Taker list of matches, find the shared match, click on the shared match profile and then find the matches that form the row of names on the Test-Taker side of the diagram. How does one then find the match list for the 1C1R to repeat the process on the 1C1R side of the diagram without having 1C1R’s log-in info? What am I missing? Thanks!
You can’t repeat the process on the 1C1R side of the diagram without having access to 1C1R’s account. But, that doesn’t mean you can’t use this. If I didn’t have access to 1C1R’s results, the only name I would have lost in this particular analysis is Hop.
Blaine, I see your process, however, as Ted above asked if you don’t have access how can you know who 1C1R’s matches are? How do you even know Hop would be the only one missing since you HAD 1C1R’s DNA results? Thanks
I would love to see the answer to this question!
Blaine,
I’m drinking through a fire hose with this tool. I have 500 Hints and another 100 or so I’ve figured out. In each profile in put the cousinship and CA surnames on the first line of the Notes. I then gold star Matches with CAs. Then, when I check the Share Matches, I can click on the little page icon for each Match with a Note and quickly check those with CAs. ALL of your Matches will have the Shared Matches link – even those beyond 4C – so you can check distant cousins for Shared Matches with your Notes. When I get a group, I message them, say I have a group and am doing analysis on the DNA that will help them, if they’ll upload to GEDmatch. I spent an hour on the phone this morning walking a Match through the process. In 10 minutes he had a kit number, and 3 minutes later I had the segment data, and in 2 more minutes his ancestry line was in my spreadsheet next to another Match with the same, unusual, CA. Bingo! Not the end of the story of course – next I’ll pulse the other Matches in that TG and focus on that TG. I cannot keep up with these “opportunities”
You have a great blogpost here!!
Thank you Blaine. I was so glad to see this post!
I’ve been helping an adopted friend to find his birth father. His bio-mom tested. He has 5, 2nd matches (who don’t match bio-mom) who all have one couple in common. (Thank goodness for folks who are willing to share their trees and answer all of my emails!) There are at this time 2 potential fathers. Both have brickwalls on the paternal side. So I’ve been trying to use shared ancestor hints to group matches (the adoptee has +700 4th cousin matches) together in a similar fashion as you’ve illustrated. Getting my mind around all of the data has been challenging.
My husband codes so we’ve had quite a few conversations about how to scrape data, but haven’t gotten far. I was hoping that DNAgedcom utility would help, but the Ancestry function has been offline for months now. Thanks again!
I’ve been using the “mirror tree” concept with those matches that DO NOT match bio-mom or the 5, 2nd cousins, hoping to find common surnames and locations.
I love this tool. As I grew branches on my tree and verified my “leaves,” I made notes on all of my connections stating person(s) through whom we connect and cousin position status, as well as cM and segment info. I then began using the shared matches, and contacting those without trees, “Based on shared matches comparison it appears we connect through (names) who were my (identify generation) grandparent(s).”
I have had several people write back verifying connection, finally uploading their tree, or providing name of person with same surname and a birth date, and I have discovered the connection and added them to my tree. (I email this person with what I find and Ancestry usually provides a few new leaves. ) I am very careful looking at the cM’s as hints to verify cousin status, ex: 2c1x. Also, I have had individual person connections because, (however many g’s grandparent) had more than one spouse. Also, I ask it they are on Gedmatch and provide my #. Eventually I hope to build a chromosome map using all this info. This info has put me in contact with several adopted cousins and I help what little I can.
Thanks Barbara, this is really helpful. I haven’t been noting the cM and segment info (doh!). I also like your idea of messaging people once you know they are part of a cluster.
A consistent and straightforward approach to figuring things out. Thank you, Blaine.
It would be a lot easier if Ancestry would just release the actual chromosome data.
A great method for using DNA to help identify biological parents in old (100 years) adoptions. The only method I’ve come up with, suggestions on others??
Blaine,
One of the reasons I programmed the Match-O-Matic tool in the DNAgedcom client was my wife and I had been “collecting” accesses to a LOT of other people’s Ancestry DNA results to the point where we had full access to a dozen or so descendants of one known 4x Great Grandparent couple. I wanted to see what I could do with those Ancestry results. So I downloaded everyone’s Ancestry matches and looked at unions (of siblings) and intersections with other descendants. My wife has over 20,000 matches. The fact that you have to use caution with this is highlighted by the fact that I could pick any pair of kits – even people with no (known) relationship such as my wife and myself, and you would still get about 50 intersects – mostly very distant. Colonial endogamy (or, as my wife calls it, “Dog-gone-amy”) really comes into play out beyond 4th cousin. So I wonder whether much more can be learned by having all the shared matches instead of just those limited to 4th cousin or closer? I’m going to give your Shared Matches network approach a go – it has the advantage that you don’t HAVE to have access to everyone’s full results which is cool!
Don
Don,
Do let me know how you make out with this! I always enjoy your insight!
And, notably, the distant intersects is exactly why Ancestry caps the Shared Matches at 4th cousins. I think with number crunching this issue could be controlled somewhat, but of course people using the Shared Matches tool at Ancestry usually aren’t doing much number crunching!
Blaine
To both of you- (Don you already know this though, I think)- Being an “Ancestry DNA mostly” newly-discovered-at age 64-adoptee, I have made significant progress in just 6 months in determining both my paternal and maternal bio family lines using only Ancestry ICW lists and the users “starter” trees.
I’m going to read your article more closely, but I started by creating a “matrix” spreadsheet of my ICWs, then automated my method using Don’s fantastic DNAGedcom Client tool (which collects ICWs past 4th cousin) and crude standalone database software I built to view the ICWs and ICWs of ICWs.
I would be ecstatic if I could send you a copy of my database software for you to scrutinize, and communicate in detail with about the whole process/method. Please email me!
My DNA is on Ancestry, FTDNA, GEDMatch, DNALand, MyHeritage, and soon 23andMe, but the VAST majority and the strongest of my matches are in Ancestry. So far I think I’m a big fan of Ancestry’s Timber & Underdog algorythms. Ancestry’s such a gold mine due to sheer volume that I’ve made it a passion to see how accurate a picture of my birth family I can glean there before I use chromosome browsers.
Thank you for the excellent post! For the moment, I am primarily using the Shared Matches tool with those Ancestry matches who have also tested at other sites so that I know exactly what segments on which chromosomes we share. I have gotten some leads to explore that way…
The other thing I am doing is using the dnagedcom.com client tool (subscription only) to pull a list of all my matches from Ancestry, plus all of my applicable shared matches — more than what I can easily see on the Ancestry website.
(For example, one of my 4th cousin matches (I’ll call MM) and I appear to have only 16 shared matches; turns out we actually have 40 matches in common. Once I have the names from the dnagedcom.com tool, I can look them up on Ancestry’s website, and
“star” them — they do show up as sharing a match to MM, despite being a distant cousin to me.) Having these extra matches with this particular cousin has helped in giving me leads to possibly distinguish which cousins match the husband vs the wife of the targeted ancestral couple.
Brilliant THANK YOU! This is exactly what I was looking for – a way to export the full shared matches data.
Back a couple months, your wife is a distant cousin of mine. I believe it was my lines from Hannover. It gave me a chuckle. Least that would be easier to search then my paternal side : ) I have had luck even on maternal distant cousins- like everything depends on trees.
Just recently I got a good hit that just may crack my paternal she has no tree, but last name prickled my hairs on back of neck-yep after searching worldconnect & findagrave, now waiting for her to respond & genealogist to respond-if I hit my jackpot.
Thanks for an excellent article. I especially appreciate all the warnings to not use the shared matches to jump to unwarranted conclusion. Shared Matches is a decent tool until Ancestry has a chromosome browser.
Blaine, I am a little late to work on this, but I did sit down this past weekend and make a chart like this with some amazing results. I believe I have found evidence of a NPE for my 2nd great grandmother. At first when I read this post, I thought why isn’t he just using the AncestryDNA Helper extension on Chrome. When I put my spreadsheet together I realized it is the matches that we DON”T have in common that are so very important. Thank you for this post and for making me think outside of the box!
This is for Leeann Stebbins or anyone who can answer this….Why are the matches that you DON’T have in common so very important?
I’m guessing she means the matches that don’t ICW your other matches are extremely telling.
I found this with my 2 strongest matches- neither share the same ICW matches with each other. Because one is a half-sister & the other a 1st Cousin, these are likely my paternal and maternal family lines.
Sorry I am late to answer this Christine. The matches you don’t have in common gives you “extra” matches that you would not have known about otherwise. In other words, my 2nd cousin got pieces of DNA from our great-grandparents that I did not. Those pieces of DNA are matching testers on this line that I don’t match because I did not get those pieces.
One tip that I’ve found about viewing the Shared Matches-
If (like me) you use multiple browser “tabs” you don’t always get a “Shared Matches” display for a match if you “right-click, Open in New Tab” the View Match button.
This seems to be due to a lack of “cookie” which Ancestry uses on the Match page. Quite often using ctrl+refresh or shift+refresh of the page will fix this. But, it will ALWAYS display if you open in a new tab, use THAT tab’s window to return to your All Match page and directly click the View Match button again.
I.E. doesn’t have this issue, but I get it in Firefox, Chrome, and Opera. fwiw.
Blaine, how are you creating these charts? With Excel, mind-mapping software, Word, PowerPoint etc?
Hi Blaine, thank you for your blog post. I came across this on google. This becomes particularly complicated when you are of mixed race ancestry as it is difficult to figure out which side of the family they match you on if they are also mixed. I have a cluster I’m particularly looking at in relation to my mother. My mother is half Mauritian Creole and half English, match has known ancestry from Madagascar, we have papertrail for Madagascar via slavery to Mauritius. Mum and match have 5 matches in common 3 are Malagasy and 2 are Dominican when you bring in their shared matches as well we have a cluster of 8 people on chromosome 7. There were other shared matches but they matched on different segments so likely related through a different line. Out of the 8 people on that segment only 2 don’t match each other, they each matched everyone else just not each other which I found interesting. Still racking my brains with this but it’s interesting. However this was on 23andme so I could filter out a lot easier than I would have been able to if it was Ancestry. Ancestry shared matches have been a lot more difficult to figure out, especially as the reply rate is very low on there.
Blaine, I’ve had some success using Shared Ancestor Hints in two different ways in spite of the lack of a chromosome browser. In my situation I’ve found that GEDmatch and FTDNA are not that useful for the following reasons: (1) Ancestry.com’s database has an order of magnitude greater number of matches to me than the others, (2) there are many more user-submitted trees (often well-sourced), and (3) searching among matches (e.g., Search by surname/location), and searching individual family trees has reasonable automation and convenience.
In the one situation Shared Matches with me or my sis were useful to fill out an entire family of siblings—but I still haven’t pinpointed which sibling is my ancestor. I first used limited information about some of the siblings (mainly just a list of names from a single 2ndary source) and the family trees of Shared Matches to hypothesize additional siblings. Then I filled in the paper trails and connections among them (which no one else seemed to have attempted). I finally corroborated the results via several probate records (luckily, easily accessed online). I have tentatively broken a couple more brick walls with this method (not yet corroborated).
The other case is the search for my dad’s birth father. My first step was to identify potential triangulations (PT’s) (i.e. 2 individuals with Shared Matches to me or my sis for which MRCA could be determined by paper trails). I was quite certain that the birth father’s recent ancestors must have emigrated from Sweden (perfect match Y37-DNA with a Swede [Oct 2017]) and there are no Swedish roots in the rest of my ancestors. In all of this the “search by birth location” was particularly useful since surname matching was out of the question due to patronymic surnames. It was a slow process starting in winter of 2018 as I was only able to figure out a new PT about once a month, simply because that’s when some appropriate new person’s matching DNA had shown up! Over this period I found that I could merge several of the PT’s. Then I noted a latest merger resulted in DNA matches to descendants of two different wives of the same gentleman X, thus pinpointing him as my potential ancestor [Dec 2018]. This is closely related to the technique of finding a marriage between two different families with DNA matches to a perp, made famous by CeCe Moore in her 60 minutes interview about using DNA to identify criminals, based on technique she’d used in adoptions. By a second more direct use of CeCe’s technique I was able to pinpoint the son (of X) and his wife W (through DNA matches via W) as my dad’s potential grandparents, leaving now just two grandsons of X as the potential birth father [Jan 2019]. My thanks to all the researchers who laboriously created the user-trees—especially Swedish family trees from original parish records—that I was able to access at Ancestry.com! And thanks to the potential cousins who submitted their DNA!
There is still a lot of work to verify my Dad’s birth father: (1) I’ve only verified the single link via W with several bona fide triangulations at GEDmatch [Feb 2019], (2) there are only 20 DNA matches in the potential family tree (largest 170 cM), and (3) I have yet to contact living potential relatives.
As you stated, you must be very careful about jumping to any conclusions about the limited DNA evidence provided by Ancestry without doing bona fide triangulations or other verification. But all in all the use of Shared Matches can be very useful, if only to narrow down the search process in a number of situations.
I have matches on Ancestry that are 5-8th cousin’s. I tend to ignore them because most people have no tree’s & no matching surnames (based on those that I have contacted.) To me this article didn’t truly answer why we have some matches that we don’t share any “shared” matches of course, I’ll figure out the why’s the more I do & when I break down & ask one of them to see if we can figure out how we connect.
I have found a lot of skeleton’s in my family tree, several kids put up for adoption, discovered my husband’s “real” father, that was a shock to all of us & the bio father. Mom was “well, I just assumed….” & “sorry for keeping you from knowing your bio-father”. Like that makes it better LOl
Discovered an Uncle fathered a kid he was never told about too.
Good & not so good (for some families) can be discovered the more things change & get tested too.